1.17. Модели нейронных сетей (с учителем) ¶
Предупреждение
Эта реализация не предназначена для крупномасштабных приложений. В частности, scikit-learn не поддерживает GPU. Чтобы узнать о гораздо более быстрых реализациях на базе графического процессора, а также о фреймворках, предлагающих гораздо большую гибкость для создания архитектур глубокого обучения, см. Связанные проекты .
1.17.1. Многослойный персептрон
Многослойный персептрон (MLP) — это алгоритм обучения с учителем, который изучает функцию $f(\cdot): R^m \rightarrow R^o$ обучением на наборе данных, где m — количество измерений для ввода и o- количество размеров для вывода. Учитывая набор функций $X = {x_1, x_2, …, x_m}$ и цель $y$, он может изучить аппроксиматор нелинейной функции для классификации или регрессии. Он отличается от логистической регрессии тем, что между входным и выходным слоями может быть один или несколько нелинейных слоев, называемых скрытыми слоями. На рисунке 1 показан MLP с одним скрытым слоем со скалярным выходом.
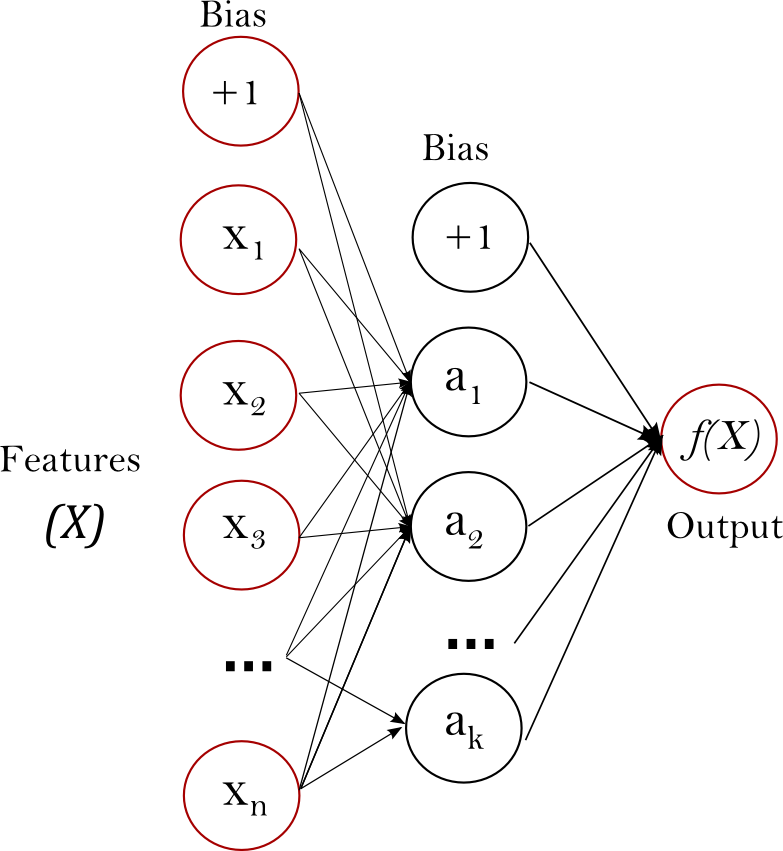
Самый левый слой, известный как входной, состоит из набора нейронов ${x_i | x_1, x_2, …, x_m}$ представляющие входные функции. Каждый нейрон в скрытом слое преобразует значения из предыдущего слоя с взвешенным линейным суммированием $w_1x_1 + w_2x_2 + … + w_mx_m$, за которой следует нелинейная функция активации $g(\cdot):R \rightarrow R$ — как функция гиперболического загара. Выходной слой получает значения из последнего скрытого слоя и преобразует их в выходные значения.
Модуль содержит публичные атрибуты coefs_ и intercepts_. coefs_список весовых матриц, где весовая матрица с индексомi представляет собой веса между слоями i и слой $i+1$. intercepts_ список векторов смещения, где вектор с индексом $i$ представляет значения смещения, добавленные к слою $i+1$.
Преимущества многослойного перцептрона:
- Возможность изучать нелинейные модели.
- Возможность изучения моделей в режиме реального времени (онлайн-обучение) с использованием
partial_fit.
К недостаткам многослойного персептрона (MLP) можно отнести:
- MLP со скрытыми слоями имеют невыпуклую функцию потерь, когда существует более одного локального минимума. Поэтому разные инициализации случайных весов могут привести к разной точности проверки.
- MLP требует настройки ряда гиперпараметров, таких как количество скрытых нейронов, слоев и итераций.
- MLP чувствителен к масштабированию функций.
См. Раздел «Советы по практическому использованию», в котором рассматриваются некоторые из этих недостатков.
1.17.2. Классификация
Класс MLPClassifier реализует алгоритм многослойного перцептрона (MLP), который обучается с использованием обратного распространения .
MLP обучается на двух массивах: массив X размера (n_samples, n_features), который содержит обучающие образцы, представленные как векторы признаков с плавающей запятой; и массив y размера (n_samples,), который содержит целевые значения (метки классов) для обучающих выборок:
>>> from sklearn.neural_network import MLPClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(5, 2), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(5, 2), random_state=1,
solver='lbfgs')После подгонки (обучения) модель может предсказывать метки для новых образцов:
>>> clf.predict([[2., 2.], [-1., -2.]]) array([1, 0])
MLP может подгонять нелинейную модель к обучающим данным. clf.coefs_ содержит весовые матрицы, составляющие параметры модели:
>>> [coef.shape for coef in clf.coefs_] [(2, 5), (5, 2), (2, 1)]
В настоящее время MLPClassifier поддерживает только функцию потерь кросс-энтропии, которая позволяет оценивать вероятность путем запуска predict_proba метода.
MLP тренирует с использованием обратного распространения ошибки. Точнее, он тренируется с использованием некоторой формы градиентного спуска, а градиенты вычисляются с использованием обратного распространения. Для классификации он минимизирует функцию потерь кросс-энтропии, давая вектор оценок вероятности $P(y|x)$ за образец $x$:
>>> clf.predict_proba([[2., 2.], [1., 2.]])
array([[1.967...e-04, 9.998...-01],
[1.967...e-04, 9.998...-01]])MLPClassifier поддерживает мультиклассовую классификацию, применяя Softmax в качестве выходной функции.
Кроме того, модель поддерживает классификацию с несколькими метками, в которой образец может принадлежать более чем одному классу. Для каждого класса необработанные выходные данные проходят через логистическую функцию. Значения, большие или равные 0.5, округляются до 1, в противном случае — до 0. Для прогнозируемых выходных данных выборки индексы, в которых указано значение, 1 представляют назначенные классы этой выборки:
>>> X = [[0., 0.], [1., 1.]]
>>> y = [[0, 1], [1, 1]]
>>> clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
... hidden_layer_sizes=(15,), random_state=1)
...
>>> clf.fit(X, y)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(15,), random_state=1,
solver='lbfgs')
>>> clf.predict([[1., 2.]])
array([[1, 1]])
>>> clf.predict([[0., 0.]])
array([[0, 1]])См. Примеры ниже и строку документации MLPClassifier.fit для получения дополнительной информации.
Примеры
1.17.3. Регрессия
Класс MLPRegressor реализует многослойный перцептрон (MLP), который обучается с использованием обратного распространения без функции активации в выходном слое, что также можно рассматривать как использование функции идентификации в качестве функции активации. Следовательно, он использует квадратную ошибку как функцию потерь, а на выходе представляет собой набор непрерывных значений.
MLPRegressor также поддерживает регрессию с несколькими выходами, при которой в выборке может быть более одной цели.
1.17.4. Регуляризация
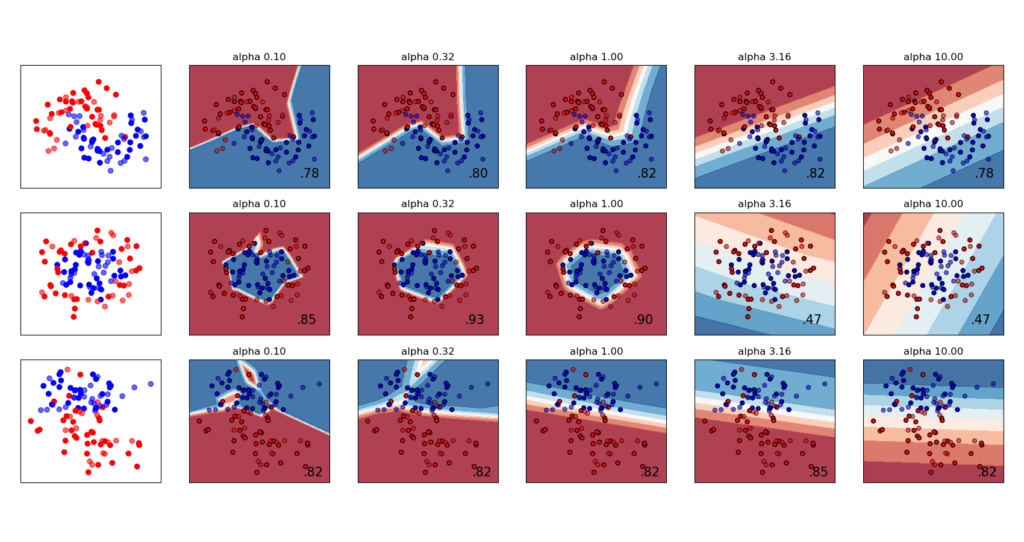
Оба MLPRegressor и MLPClassifier используют параметр alpha для термина регуляризации (L2-регуляризация), который помогает избежать переобучения, штрафуя веса большими величинами. Следующий график отображает изменяющуюся функцию решения со значением альфа.
См. Примеры ниже для получения дополнительной информации.
1.17.5. Алгоритмы
MLP тренирует с использованием стохастического градиентного спуска , Адама или L-BFGS . Стохастический градиентный спуск (SGD) обновляет параметры, используя градиент функции потерь по отношению к параметру, который требует адаптации, т. Е.
$$w \leftarrow w — \eta (\alpha \frac{\partial R(w)}{\partial w} + \frac{\partial Loss}{\partial w})$$
где $\eta$ — это скорость обучения, которая контролирует размер шага при поиске в пространстве параметров. $Loss$ — функция потерь, используемая для сети.
Более подробную информацию можно найти в документации SGD.
Adam похож на SGD в том смысле, что это стохастический оптимизатор, но он может автоматически регулировать количество для обновления параметров на основе адаптивных оценок моментов более низкого порядка.
С SGD или Adam обучение поддерживает онлайн и мини-пакетное обучение.
L-BFGS — это решающая программа, которая аппроксимирует матрицу Гессе, которая представляет собой частную производную второго порядка функции. Кроме того, он аппроксимирует обратную матрицу Гессе для обновления параметров. Реализация использует версию L-BFGS Scipy .
Если выбран решатель «L-BFGS», обучение не поддерживает ни онлайн, ни мини-пакетное обучение.
1.17.6. Сложность
Предположим, есть $n$ обучающие образцы, $m$ Особенности, $k$ скрытые слои, каждый из которых содержит $h$ нейроны — для простоты и $o$ выходные нейроны. Временная сложность обратного распространения ошибки равна $O(n\cdot m \cdot h^k \cdot o \cdot i)$, где $i$- количество итераций. Поскольку обратное распространение имеет высокую временную сложность, рекомендуется начинать с меньшего количества скрытых нейронов и нескольких скрытых слоев для обучения.
1.17.7. Математическая постановка
Учитывая набор обучающих примеров $(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)$ где $x_i \in \mathbf{R}^n$ а также $y_i \in {0, 1}$, один скрытый слой один скрытый нейрон MLP изучает функцию $f(x) = W_2 g(W_1^T x + b_1) + b_2$ где $W_1 \in \mathbf{R}^m$ а также $W_2, b_1, b_2 \in \mathbf{R}$ параметры модели. $W_1, W_2$ представляют веса входного слоя и скрытого слоя соответственно; а также $b_1, b_2$ представляют смещение, добавленное к скрытому слою и выходному слою соответственно. $g(\cdot) : R \rightarrow R$- функция активации, установленная по умолчанию как гиперболический загар. Это дается как,
$$g(z)= \frac{e^z-e^{-z}}{e^z+e^{-z}}$$
Для бинарной классификации $f(x)$ проходит через логистическую функцию $g(z)=1/(1+e^{-z})$ для получения выходных значений от нуля до единицы. Порог, установленный на 0,5, будет назначать образцы выходных данных, превышающих или равных 0,5, положительному классу, а остальные — отрицательному классу.
Если классов больше двух, $f(x)$ сам был бы вектором размера (n_classes,). Вместо того, чтобы проходить через логистическую функцию, он проходит через функцию softmax, которая записывается как,
$$\text{softmax}(z)i = \frac{\exp(z_i)}{\sum{l=1}^k\exp(z_l)}$$
где $z_i$ представляет $i$-тый элемент ввода в softmax, который соответствует классу $i$, а также $K$ количество классов. Результатом является вектор, содержащий вероятности, которые выбирают $x$ принадлежат к каждому классу. На выходе получается класс с наибольшей вероятностью.
В регрессии результат остается как $f(x)$; следовательно, функция активации выхода — это просто функция идентичности.
MLP использует разные функции потерь в зависимости от типа проблемы. Функция потерь для классификации — это кросс-энтропия, которая в двоичном случае задается как,
$$Loss(\hat{y},y,W) = -y \ln {\hat{y}} — (1-y) \ln{(1-\hat{y})} + \alpha ||W||_2^2$$
где $\alpha ||W||_2^2$ это термин L2-регуляризации (также известный как штраф), который штрафует сложные модели; а также $\alpha > 0$ неотрицательный гиперпараметр, определяющий величину штрафа.
Для регрессии MLP использует функцию потерь квадратичной ошибки; написано как,
$$Loss(\hat{y},y,W) = \frac{1}{2}||\hat{y} — y ||_2^2 + \frac{\alpha}{2} ||W||_2^2$$
Начиная с начальных случайных весов, многослойный персептрон (MLP) минимизирует функцию потерь, многократно обновляя эти веса. После вычисления потерь при обратном проходе они распространяются с выходного уровня на предыдущие уровни, предоставляя каждому параметру веса значение обновления, предназначенное для уменьшения потерь.
При градиентном спуске градиент $\nabla Loss_{W}$ потери по весам вычисляется и вычитается из $W$. Более формально это выражается как,
$$W^{i+1} = W^i — \epsilon \nabla {Loss}_{W}^{i}$$
где $i$ — шаг итерации, а ϵ скорость обучения со значением больше 0.
Алгоритм останавливается, когда достигает заданного максимального количества итераций; или когда улучшение потерь ниже определенного небольшого числа.
1.17.8. Советы по практическому использованию
- Многослойный персептрон чувствителен к масштабированию функций, поэтому настоятельно рекомендуется масштабировать ваши данные. Например, масштабируйте каждый атрибут во входном векторе X до [0, 1] или [-1, +1] или стандартизируйте его, чтобы он имел среднее значение 0 и дисперсию 1. Обратите внимание, что вы должны применить такое же масштабирование к набору тестов для значимые результаты. Можно использовать
StandardScalerдля стандартизации.
>>> from sklearn.preprocessing import StandardScaler >>> scaler = StandardScaler() >>> # Don't cheat - fit only on training data >>> scaler.fit(X_train) >>> X_train = scaler.transform(X_train) >>> # apply same transformation to test data >>> X_test = scaler.transform(X_test)
- Альтернативный и рекомендуемый подход — использовать
StandardScalerвPipeline - Нахождение разумного параметра регуляризации $\alpha$ лучше всего использовать
GridSearchCV, обычно в диапазоне10.0 ** -np.arange(1, 7) - Эмпирическим
L-BFGSпутем мы заметили, что это происходит быстрее и с лучшими решениями на небольших наборах данных. Однако для относительно больших наборов данныхAdamэто очень надежно. Обычно он быстро сходится и дает довольно хорошую производительность.SGDс импульсом или импульсом нестерова, с другой стороны, может работать лучше, чем эти два алгоритма, если скорость обучения настроена правильно.
1.17.9. Больше контроля с warm_start
Если вы хотите получить больше контроля над критериев остановки или скорости обучения в СГД, или хотите сделать дополнительный мониторинг, используя warm_start=True и max_iter=1 и переборе сами могут быть полезны:
>>> X = [[0., 0.], [1., 1.]] >>> y = [0, 1] >>> clf = MLPClassifier(hidden_layer_sizes=(15,), random_state=1, max_iter=1, warm_start=True) >>> for i in range(10): ... clf.fit(X, y) ... # additional monitoring / inspection MLPClassifier(...
Рекомендации
- «Изучение представлений путем обратного распространения ошибок». Рамелхарт, Дэвид Э., Джеффри Э. Хинтон и Рональд Дж. Уильямс.
- «Стохастический градиентный спуск» Л. Ботто — Интернет-сайт, 2010.
- «Обратное распространение» Эндрю Нг, Цзицюань Нгиам, Чуан Ю Фу, Ифань Май, Кэролайн Суен — веб-сайт, 2011 г.
- «Efficient BackProp» Ю. ЛеКун, Л. Ботту, Г. Орр, К. Мюллер — В нейронных сетях: уловки торговли 1998.
- «Адам: метод стохастической оптимизации». Кингма, Дидерик и Джимми Ба. Препринт arXiv arXiv: 1412.6980 (2014).