2.5 Декомпозиция сигналов на компоненты (Проблема матричной факторизации) ¶
2.5.1. Анализ главных компонентов (PCA — Principal component analysis)
2.5.1.1. Точный PCA и вероятностная интерпретация
PCA используется для разложения многомерного набора данных на набор последовательных ортогональных компонентов, которые объясняют максимальную величину дисперсии. В scikit-learn PCA реализован как объект- преобразователь, который изучает $n$ компоненты в своем fit методе и могут использоваться для новых данных, чтобы проецировать их на эти компоненты.
PCA центрирует, но не масштабирует входные данные для каждой функции перед применением SVD. Необязательный параметр whiten=True позволяет проецировать данные в единичное пространство, масштабируя каждый компонент до единичной дисперсии. Это часто бывает полезно, если последующие модели делают сильные предположения об изотропии сигнала: это, например, случай для машин опорных векторов с ядром RBF и алгоритмом кластеризации K-средних.
Ниже приведен пример набора данных радужной оболочки глаза, который состоит из 4 функций, спроецированных на 2 измерения, которые объясняют наибольшую разницу:
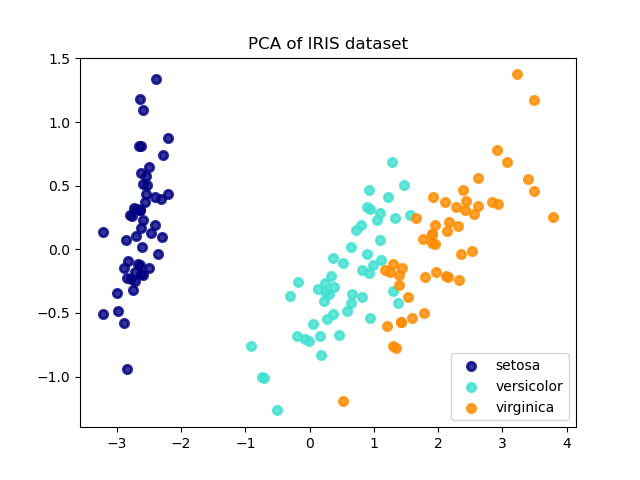
PCA Объект также обеспечивает вероятностную интерпретацию PCA , который может дать вероятность данных на основе количества дисперсии , что объясняет. Таким образом, он реализует метод оценки, который можно использовать при перекрестной проверке:
Примеры:
2.5.1.2. Инкрементальный PCA
PCA Объект очень полезен, но имеет определенные ограничения для больших наборов данных. Самым большим ограничением является то, что PCA поддерживается только пакетная обработка, что означает, что все обрабатываемые данные должны умещаться в основной памяти. IncrementalPCA Объект использует различные формы обработки и позволяет частичные вычисления , которые почти точно соответствуют результатам PCA при обработке данных в minibatch моде. IncrementalPCA позволяет реализовать анализ основных компонентов вне ядра посредством:
- Используя свой
partial_fitметод для фрагментов данных, последовательно извлекаемых с локального жесткого диска или сетевой базы данных. - Вызов его метода fit для разреженной матрицы или файла с отображением памяти с использованием
numpy.memmap.
IncrementalPCA сохраняет только оценки дисперсии компонентов и шума в порядке explained_variance_ratio_ постепенного обновления . Вот почему использование памяти зависит от количества выборок в пакете, а не от количества выборок, которые должны быть обработаны в наборе данных.
Как и в случае PCA, IncrementalPCA центрирует, но не масштабирует входные данные для каждой функции перед применением SVD.
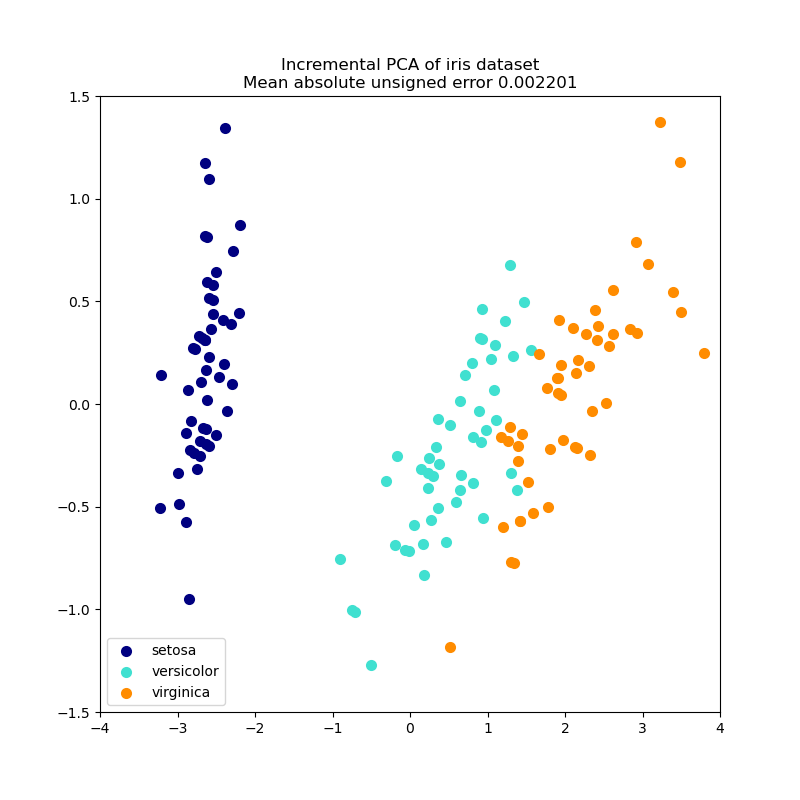
Примеры:
IncrementalPCA— Инкрементальный PCA
2.5.1.3. PCA с использованием рандомизированного SVD
Часто бывает интересно проецировать данные в пространство меньшей размерности, которое сохраняет большую часть дисперсии, отбрасывая сингулярный вектор компонентов, связанных с более низкими сингулярными значениями.
Например, если мы работаем с изображениями с уровнем серого размером 64×64 пикселя для распознавания лиц, размерность данных составляет 4096, и обучение векторной машины поддержки RBF на таких широких данных является медленным. Кроме того, мы знаем, что внутренняя размерность данных намного ниже 4096, поскольку все изображения человеческих лиц выглядят в некоторой степени одинаково. Образцы лежат на коллекторе гораздо меньшего размера (например, около 200). Алгоритм PCA можно использовать для линейного преобразования данных при одновременном уменьшении размерности и сохранении большей части объясненной дисперсии.
Класс, PCA используемый с необязательным параметром svd_solver='randomized', очень полезен в этом случае: поскольку мы собираемся отбросить большинство сингулярных векторов, гораздо эффективнее ограничить вычисление приближенной оценкой сингулярных векторов, мы будем продолжать фактически выполнять преобразование .
Например, ниже показаны 16 образцов портретов (с центром вокруг 0,0) из набора данных Olivetti. Справа — первые 16 сингулярных векторов, преобразованных в портреты. Поскольку нам нужны только первые 16 сингулярных векторов набора данных с размером $n_{samples} = 400$ а также $n_{features} = 64 \times 64 = 4096$, время расчета меньше 1 секунды:


Если мы отметим $n_{\max} = \max(n_{\mathrm{samples}}, n_{\mathrm{features}})$ а также $n_{\min} = \min(n_{\mathrm{samples}}, n_{\mathrm{features}})$, Временная сложность рандомизированного PCA является $O(n_{\max}^2 \cdot n_{\mathrm{components}})$ вместо $O(n_{\max}^2 \cdot n_{\min})$ для точного метода, реализованного в PCA.
Объем памяти рандомизированного типа PCA также пропорционален $2 \cdot n_{\max} \cdot n_{\mathrm{components}}$ вместо $n_{\max}\cdot n_{\min}$ для точного метода.
Примечание: реализация inverse_transform в PCA с svd_solver='randomized' не является точным обратным преобразованием transform даже when whiten=False (по умолчанию).
Примеры:
Рекомендации:
2.5.1.4. Ядро PCA
KernelPCA является расширением PCA, которое обеспечивает снижение нелинейной размерности за счет использования ядер (см. Парные метрики, Сродства и Ядра ). Он имеет множество приложений, включая шумоподавление, сжатие и структурированное прогнозирование (оценка зависимости ядра). KernelPCA поддерживает как transform так и inverse_transform.
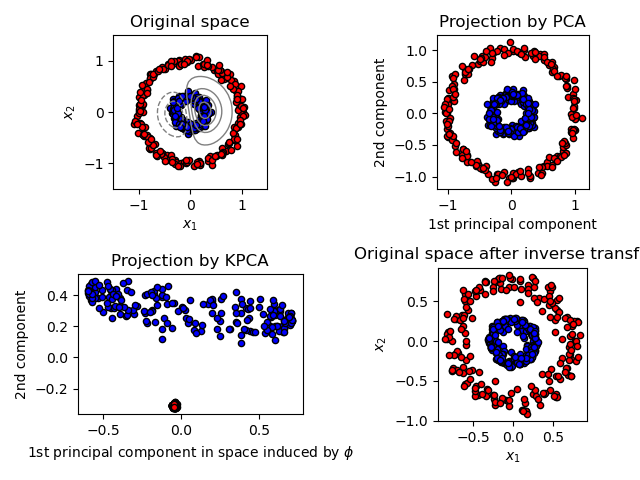
Примеры:
2.5.1.5. Анализ разреженных основных компонентов (SparsePCA и MiniBatchSparsePCA)
SparsePCA представляет собой вариант PCA с целью извлечения набора разреженных компонентов, которые наилучшим образом восстанавливают данные.
Мини-пакетный разреженный PCA ( MiniBatchSparsePCA) — это SparsePCA более быстрый, но менее точный вариант . Повышенная скорость достигается путем перебора небольших фрагментов набора функций в течение заданного количества итераций.
Недостаток анализа главных компонентов (PCA) состоит в том, что компоненты, извлеченные этим методом, имеют исключительно плотные выражения, т. е. они имеют ненулевые коэффициенты, когда выражаются как линейные комбинации исходных переменных. Это может затруднить интерпретацию. Во многих случаях реальные базовые компоненты можно более естественно представить как разреженные векторы; например, при распознавании лиц компоненты могут естественным образом отображаться на части лиц.
Редкие основные компоненты дают более скупое, интерпретируемое представление, четко подчеркивая, какие из исходных функций способствуют различию между выборками.
В следующем примере показаны 16 компонентов, извлеченных с помощью разреженного PCA из набора данных лиц Olivetti. Можно увидеть, как член регуляризации порождает много нулей. Кроме того, естественная структура данных заставляет ненулевые коэффициенты быть смежными по вертикали. Модель не обеспечивает этого математически: каждый компонент является вектор $h \in \mathbf{R}^{4096}$, и нет понятия вертикальной смежности, кроме как во время удобной для человека визуализации в виде изображений размером 64×64 пикселей. Тот факт, что показанные ниже компоненты выглядят локальными, является эффектом внутренней структуры данных, которая позволяет таким локальным шаблонам минимизировать ошибку восстановления. Существуют нормы, вызывающие разреженность, которые учитывают смежность и различные виды структуры; см. [Jen09] для обзора таких методов. Дополнительные сведения об использовании Sparse PCA см. В разделе «Примеры» ниже.


Обратите внимание, что существует множество различных формулировок проблемы разреженного PCA. Реализованный здесь основан на [Mrl09] . Решенная задача оптимизации — это задача PCA (изучение словаря) сℓ1 штраф по компонентам:
$$\begin{split}(U^*, V^*) = \underset{U, V}{\operatorname{arg\,min\,}} & \frac{1}{2} ||X-UV||^{2}_2+\alpha||V||_1 \ \text{subject to } & ||U_k||_2 = 1 \text{ for all } 0 \leq k < n_{components}\end{split}$$
Вызывающая разреженность $\ell_1$ норма также защищает обучающие компоненты от шума, когда доступно несколько обучающих выборок. Степень пенализации (и, следовательно, разреженность) можно отрегулировать с помощью гиперпараметра alpha. Маленькие значения приводят к мягко регуляризованной факторизации, в то время как большие значения сжимают многие коэффициенты до нуля.
Примечание
Несмотря на то, что в духе онлайн-алгоритма, класс MiniBatchSparsePCA не реализуется, partial_fit потому что алгоритм находится в оперативном режиме в направлении функций, а не в направлении выборки.
Примеры:
Рекомендации:
- Mrl09 «Изучение онлайн-словарей для разреженного кодирования» Дж. Майрал, Ф. Бах, Дж. Понсе, Дж. Сапиро, 2009 г.
- Jen09 «Структурированный разреженный анализ главных компонентов» Р. Дженаттон, Г. Обозински, Ф. Бах, 2009 г.
2.5.2. Усеченное сингулярное разложение и латентно — семантический анализ
TruncatedSVD реализует вариант разложения по сингулярным значениям (SVD), который вычисляет только k наибольшие сингулярные значения, где k — параметр, задаваемый пользователем.
Когда усеченный SVD применяется к матрицам терминов-документов (возвращаемых CountVectorizerили TfidfVectorizer), это преобразование известно как скрытый семантический анализ (LSA), поскольку оно преобразует такие матрицы в «семантическое» пространство низкой размерности. В частности, известно, что LSA борется с эффектами синонимии и многозначности (оба из которых примерно означают наличие нескольких значений для каждого слова), из-за которых матрицы терминов-документов становятся слишком разреженными и демонстрируют плохое сходство по таким показателям, как косинусное сходство.
Примечание
LSA также известно как скрытое семантическое индексирование, LSI, хотя строго это относится к его использованию в постоянных индексах для целей поиска информации.
Математически усеченный SVD применяется к обучающим выборкам $X$ производит приближение низкого ранга $X$:
$$X \approx X_k = U_k \Sigma_k V_k^\top$$
После этой операции $U_k \Sigma_k$ преобразованный обучающий набор с kфункции (вызываемые n_components в API).
Чтобы также преобразовать тестовый набор $X$, мы умножаем его на $V_k$:
$$X’ = X V_k$$
Примечание
В большинстве трактовок LSA в литературе по обработке естественного языка (NLP) и информационному поиску (IR) оси матрицы меняются местами $X$ чтобы он имел форму n_features × n_samples. Мы представляем LSA другим способом, который лучше соответствует API scikit-learn, но найденные единичные значения совпадают.
TruncatedSVD очень похожа на PCA, но отличается тем, что матрицаXне нужно центрировать. Когда по столбцам (по признакам) средние значенияXвычитаются из значений признаков, усеченный SVD в результирующей матрице эквивалентен PCA. На практике это означает, что TruncatedSVD преобразователь принимает scipy.sparseматрицы без необходимости их уплотнения, поскольку уплотнение может заполнить память даже для коллекций документов среднего размера.
Несмотря на то, что TruncatedSVD преобразователь работает с любой матрицей функций, рекомендуется использовать его для матриц tf–idf по сравнению с необработанными счетчиками частоты в настройках LSA / обработки документов. В частности, следует включить сублинейное масштабирование и обратную частоту документа ( sublinear_tf=True, use_idf=True), чтобы приблизить значения функций к гауссовскому распределению, компенсируя ошибочные предположения LSA о текстовых данных.
Рекомендации:
- Кристофер Д. Мэннинг, Прабхакар Рагхаван и Хинрих Шютце (2008), Введение в поиск информации , Cambridge University Press, глава 18: Разложение матриц и скрытое семантическое индексирование
2.5.3. Изучение словаря
2.5.3.1. Разреженное кодирование с предварительно вычисленным словарем
Объект SparseCoder является оценкой , которая может быть использована для преобразования сигналов в разреженную линейную комбинацию атомов с фиксированным, предварительно вычислен словарем , такой как дискретный вейвлетом — основа. Следовательно, этот объект не реализует fit метод. Преобразование сводится к проблеме разреженного кодирования: поиск представления данных в виде линейной комбинации как можно меньшего числа атомов словаря. Все варианты обучения словарю реализуют следующие методы преобразования, управляемые через transform_method параметр инициализации:
- Преследование ортогонального соответствия (Преследование ортогонального соответствия (OMP))
- Регрессия наименьшего угла (наименьшая угловая регрессия)
- Лассо, вычисленное с помощью регрессии наименьшего угла
- Лассо с использованием координатного спуска (Лассо)
- Пороговое значение
Пороговая обработка выполняется очень быстро, но не дает точных реконструкций. В литературе было показано, что они полезны для задач классификации. Для задач реконструкции изображений поиск ортогонального соответствия дает наиболее точную и несмещенную реконструкцию.
Объекты обучения словаря предлагают через split_code параметр возможность разделить положительные и отрицательные значения в результатах разреженного кодирования. Это полезно, когда словарное обучение используется для извлечения функций, которые будут использоваться для контролируемого обучения, потому что это позволяет алгоритму обучения присваивать разные веса отрицательным нагрузкам конкретного атома, от до соответствующей положительной нагрузки.
Код разделения для одного образца имеет длину 2 * n_components и строится по следующему правилу: сначала вычисляется обычный код длины n_components. Затем первые записи n_components заполняются положительной частью split_code обычного кодового вектора. Вторая половина кода разделения заполняется отрицательной частью вектора кода, только с положительным знаком. Следовательно, split_code неотрицателен.
2.5.3.2. Общее изучение словаря
Dictionary Learning ( DictionaryLearning) — это проблема матричной факторизации, которая сводится к поиску (обычно переполненного) словаря, который будет хорошо работать при редком кодировании подобранных данных.
Предполагается, что представление данных в виде разреженных комбинаций атомов из переполненного словаря является способом работы первичной зрительной коры головного мозга млекопитающих. Следовательно, словарное обучение, применяемое к фрагментам изображения, было показано, что дает хорошие результаты в задачах обработки изображений, таких как завершение изображения, рисование и шумоподавление, а также для задач распознавания с учителем.
Изучение словаря — это проблема оптимизации, решаемая альтернативным обновлением разреженного кода в качестве решения нескольких проблем лассо с учетом исправления словаря и последующим обновлением словаря для наилучшего соответствия разреженному коду.
$$\begin{split}(U^*, V^*) = \underset{U, V}{\operatorname{arg\,min\,}} & \frac{1}{2} ||X-UV||^{2}_2+\alpha||U||_1 \ \text{subject to } & ||V_k||_2 = 1 \text{ for all } 0 \leq k < n_{\mathrm{atoms}}\end{split}$$


После использования такой процедуры для соответствия словарю преобразование представляет собой просто этап разреженного кодирования, который имеет ту же реализацию, что и все объекты изучения словаря (см. Разреженное кодирование с предварительно вычисленным словарем ).
Также возможно ограничить словарь и / или код положительными значениями для соответствия ограничениям, которые могут присутствовать в данных. Ниже приведены лица с различными ограничениями положительности. Красный цвет указывает на отрицательные значения, синий — на положительные значения, а белый — на нули.




На следующем изображении показано, как выглядит словарь, полученный из фрагментов изображения размером 4×4 пикселя, извлеченных из части изображения лица енота.

Рекомендации:
«Изучение онлайн-словарей для разреженного кодирования» Дж. Майрал, Ф. Бах, Дж. Понсе, Дж. Сапиро, 2009 г.
2.5.3.3. Мини-пакетное изучение словаря
MiniBatchDictionaryLearning реализует более быструю, но менее точную версию алгоритма изучения словаря, которая лучше подходит для больших наборов данных.
По умолчанию MiniBatchDictionaryLearning разделяет данные на мини-пакеты и оптимизирует их в интерактивном режиме, циклически перебирая мини-пакеты на указанное количество итераций. Однако на данный момент он не реализует условие остановки.
Также реализован оценщик partial_fit, который обновляет словарь, выполняя итерацию только один раз в мини-пакете. Это можно использовать для онлайн-обучения, когда данные недоступны с самого начала или когда данные не помещаются в память.
Кластеризация для изучения словаря
Обратите внимание, что при использовании обучения по словарю для извлечения представления (например, для разреженного кодирования) кластеризация может быть хорошим прокси для изучения словаря. Например, MiniBatchKMeans оценщик является эффективным с вычислительной точки зрения и реализует онлайн-обучение с помощью partial_fitметода.
Пример: онлайн-изучение словаря частей лиц
2.5.4. Факторный анализ
При обучении без учителя у нас есть только набор данных $X = {x_1, x_2, \dots, x_n}$. Как можно математически описать этот набор данных? Очень простая модель дляcontinuous latent variable $X$ является
$$x_i = W h_i + \mu + \epsilon$$
Вектор $h_i$ называется «скрытым», потому что не наблюдается. ϵ считается шумовым членом, распределенным в соответствии с гауссианом со средним 0 и ковариацией $\Psi$ (т.е. $\epsilon \sim \mathcal{N}(0, \Psi)$), $\mu$- произвольный вектор смещения. Такая модель называется «генеративной», поскольку она описывает, как $x_i$ генерируется из $h_i$. Если использовать всеxiв виде столбцов для формирования матрицы $X$ и все $h_i$ как столбцы матрицы $H$ тогда мы можем написать (с соответствующим образом определенным $M$ а также $E$):
$$\mathbf{X} = W \mathbf{H} + \mathbf{M} + \mathbf{E}$$
Другими словами, мы разложили матрицу $X$.
Если $h_i$ приведенное выше уравнение автоматически подразумевает следующую вероятностную интерпретацию:
$$p(x_i|h_i) = \mathcal{N}(Wh_i + \mu, \Psi)$$
Для полной вероятностной модели нам также необходимо априорное распределение для скрытой переменной h. Наиболее прямое предположение (основанное на хороших свойствах гауссова распределения): $h \sim \mathcal{N}(0,\mathbf{I})$. Это дает гауссову как маргинальное распределение $x$:
$$p(x) = \mathcal{N}(\mu, WW^T + \Psi)$$
Теперь, без каких-либо дополнительных предположений, идея наличия скрытой переменной $h$ было бы лишним — $x$ можно полностью смоделировать с помощью среднего и ковариации. Нам нужно наложить более конкретную структуру на один из этих двух параметров. Простое дополнительное предположение о структуре ковариации ошибок $\Psi$:
- $\Psi = \sigma^2 \mathbf{I}$: Это предположение приводит к вероятностной модели
PCA. - $\Psi = \mathrm{diag}(\psi_1, \psi_2, \dots, \psi_n)$: Эта модель называется
FactorAnalysisклассической статистической моделью. Матрицу $W$ иногда называют «матрицей факторных нагрузок».
Обе модели по существу оценивают гауссиан с ковариационной матрицей низкого ранга. Поскольку обе модели являются вероятностными, их можно интегрировать в более сложные модели, например, смесь факторных анализаторов. Получаются очень разные модели (например FastICA), если предполагаются негауссовы априорные значения для скрытых переменных.
Факторный анализ может производить аналогичные компоненты (столбцы его матрицы нагрузки) для PCA. Однако нельзя делать никаких общих заявлений об этих компонентах (например, являются ли они ортогональными):


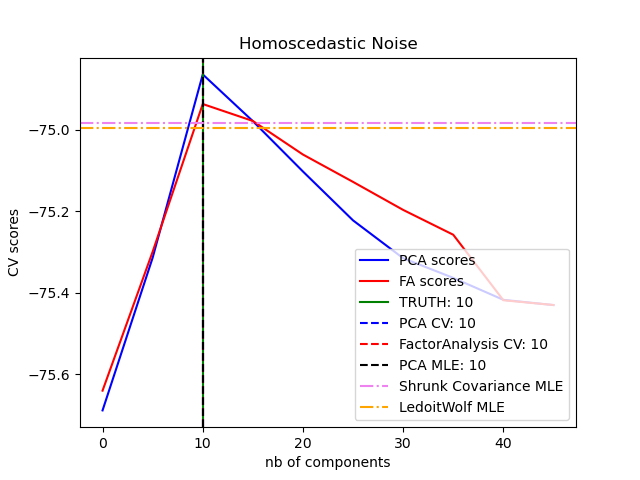
Основное преимущество факторного анализа перед ним PCA заключается в том, что он может независимо моделировать дисперсию во всех направлениях входного пространства (гетероскедастический шум):

Это позволяет лучше выбрать модель, чем вероятностный PCA при наличии гетероскедастического шума:
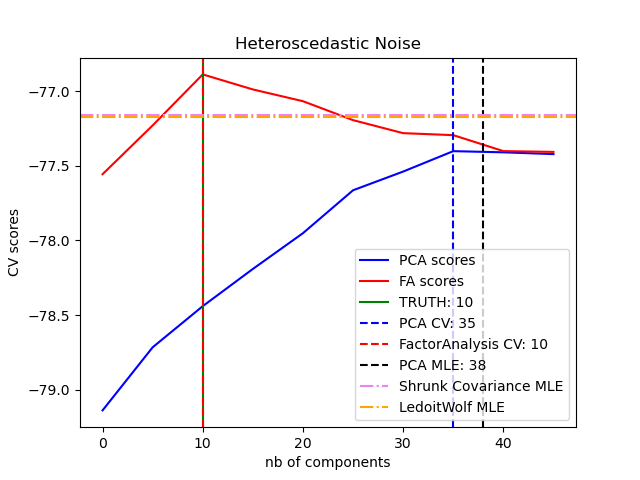
Факторный анализ часто сопровождается ротацией факторов (с параметром rotation), обычно для улучшения интерпретируемости. Например, вращение Varimax максимизирует сумму дисперсий квадратов нагрузок, т. Е. Имеет тенденцию производить более разреженные факторы, на которые влияют только несколько характеристик каждая («простая структура»). См., Например, первый пример ниже.
Примеры:
2.5.5. Независимый компонентный анализ (ICA)
Независимый компонентный анализ разделяет многомерный сигнал на аддитивные подкомпоненты, которые максимально независимы. Это реализовано в scikit-learn с использованием алгоритма Fast ICA. Обычно ICA используется не для уменьшения размерности, а для разделения наложенных сигналов. Поскольку модель ICA не включает термин «шум», для того, чтобы модель была правильной, необходимо применить отбеливание. Это можно сделать внутренне, используя аргумент whiten, или вручную, используя один из вариантов PCA.
Он обычно используется для разделения смешанных сигналов (проблема, известная как слепое разделение источников ), как в примере ниже:
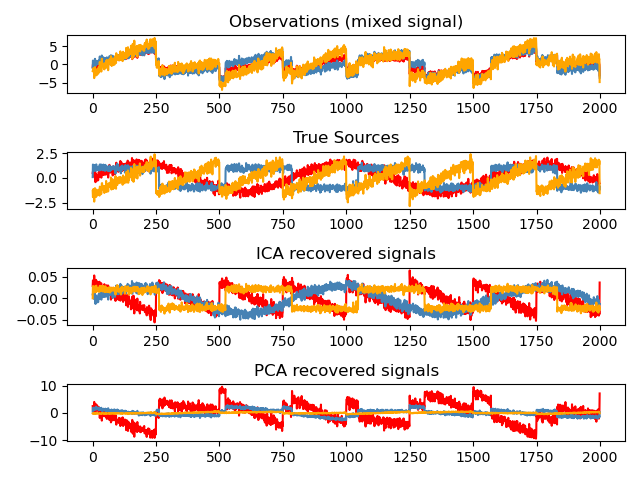
ICA также можно использовать как еще одно нелинейное разложение, которое находит компоненты с некоторой разреженностью:


Примеры:
2.5.6. Неотрицательная матричная факторизация (NMF или NNMF)
2.5.6.1. NMF с нормой Фробениуса
NMF (Источник 1) — альтернативный подход к декомпозиции, который предполагает, что данные и компоненты неотрицательны. NMF может быть подключен вместо PCA или его варианты, в тех случаях, когда матрица данных не содержит отрицательных значений. Находит разложение образцов $X$ на две матрицы $W$ а также $H$ неотрицательных элементов, оптимизируя расстояние $d$ между $X$ и матричное произведение $WH$. Наиболее широко используемая функция расстояния — это квадрат нормы Фробениуса, который является очевидным расширением евклидовой нормы на матрицы:
$$d_{\mathrm{Fro}}(X, Y) = \frac{1}{2} ||X — Y||^{2}_{\mathrm{Fro}} = \frac{1}{2} \sum_{i,j} (X_{ij} — {Y}_{ij})^2$$
В отличие от PCA этого представление вектора получается аддитивным способом, путем наложения компонентов без вычитания. Такие аддитивные модели эффективны для представления изображений и текста.
В [Hoyer, 2004] (Источник 2) было замечено, что при тщательном ограничении NMF можно получить представление набора данных на основе частей, что приводит к интерпретируемым моделям. В следующем примере показаны 16 разреженных компонентов, найденных NMF с помощью изображений в наборе данных Olivetti Faces, в сравнении с собственными гранями PCA.


Атрибут init определяет метод инициализации применяется, который имеет большое влияние на производительность способа. NMF реализует метод Разложения по неотрицательному двойному сингулярному значению. NNDSVD (Источник 4) основан на двух процессах SVD, один из которых аппроксимирует матрицу данных, а другой аппроксимирует положительные части результирующих частных коэффициентов SVD, используя алгебраическое свойство матриц единичных рангов. Базовый алгоритм NNDSVD лучше подходит для разреженной факторизации. Его варианты NNDSVDa (в котором все нули установлены равными среднему значению всех элементов данных) и NNDSVDar (в котором нули установлены для случайных возмущений, меньших, чем среднее значение данных, деленное на 100) рекомендуются в плотном дело.
Обратите внимание, что решатель мультипликативного обновления (‘mu’) не может обновлять нули, присутствующие при инициализации, поэтому он приводит к худшим результатам при использовании вместе с базовым алгоритмом NNDSVD, который вводит много нулей; в этом случае следует предпочесть NNDSVDa или NNDSVDar.
NMF также может быть инициализирован правильно масштабированными случайными неотрицательными матрицами путем установки init="random". Целочисленное начальное число или a RandomState также может быть передано random_state для контроля воспроизводимости.
In NMF, априорные значения L1 и L2 могут быть добавлены к функции потерь, чтобы упорядочить модель. Приоритет в L2 использует норму Фробениуса, в то время как предварительный вариант L1 использует поэлементную норму L1. Как и в случае ElasticNet, мы контролируем комбинацию L1 и L2 с помощью l1_ratio ($\rho$), а интенсивность регуляризации с alpha ($\alpha$) параметр. Тогда априорные условия таковы:
$$\alpha \rho ||W||_1 + \alpha \rho ||H||_1 + \frac{\alpha(1-\rho)}{2} ||W||_{\mathrm{Fro}}^2 + \frac{\alpha(1-\rho)}{2} ||H||_{\mathrm{Fro}} ^ 2$$
а регуляризованная целевая функция:
$$d_{\mathrm{Fro}}(X, WH) + \alpha \rho ||W||_1 + \alpha \rho ||H||_1 + \frac{\alpha(1-\rho)}{2} ||W||_{\mathrm{Fro}}^2 + \frac{\alpha(1-\rho)}{2} ||H||_{\mathrm{Fro}} ^ 2$$
NMF по умолчанию упорядочивает как $W$, так и $H$. Параметр regularization позволяет управлять более тонким, с которой только $W$, только $Н$, или оба могут быть регламентированы.
2.5.6.2. NMF с бета-дивергенцией
Как описано ранее, наиболее широко используемой функцией расстояния является квадрат нормы Фробениуса, которая является очевидным расширением евклидовой нормы на матрицы:
$$d_{\mathrm{Fro}}(X, Y) = \frac{1}{2} ||X — Y||_{Fro}^2 = \frac{1}{2} \sum_{i,j} (X_{ij} — {Y}_{ij})^2$$
В NMF могут использоваться и другие функции расстояния, например, (обобщенная) дивергенция Кульбака-Лейблера (KL), также называемая I-дивергенцией:
$$d_{KL}(X, Y) = \sum_{i,j} (X_{ij} \log(\frac{X_{ij}}{Y_{ij}}) — X_{ij} + Y_{ij})$$
Или расхождение Итакура-Сайто (IS):
$$d_{IS}(X, Y) = \sum_{i,j} (\frac{X_{ij}}{Y_{ij}} — \log(\frac{X_{ij}}{Y_{ij}}) — 1)$$
Эти три расстояния являются частными случаями семейства бета-расходимостей, при этом $\beta = 2, 1, 0$ соответственно (Источник 6). Бета-дивергенция определяется:
$$d_{\beta}(X, Y) = \sum_{i,j} \frac{1}{\beta(\beta — 1)}(X_{ij}^\beta + (\beta-1)Y_{ij}^\beta — \beta X_{ij} Y_{ij}^{\beta — 1})$$
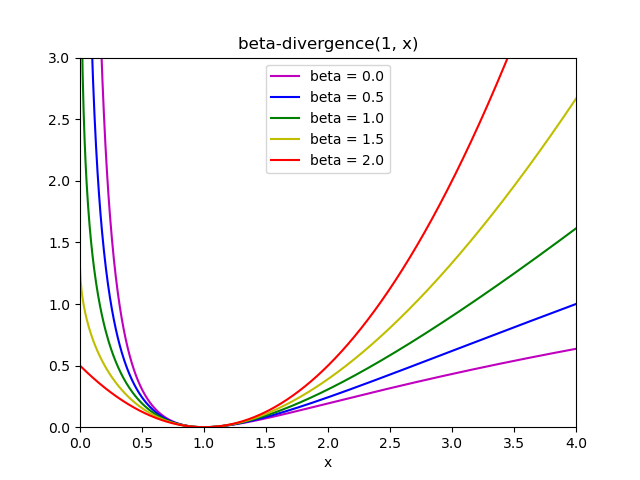
Обратите внимание, что это определение недействительно, если $\beta \in (0; 1)$, но его можно непрерывно распространить на определения $d_{KL}$ а также $d_{IS}$ соответственно.
NMF реализует два решателя с использованием координатного спуска (‘cd’) (Источник 5) и мультипликативного обновления (‘mu’) (Источник 6) . Решатель mu может оптимизировать любое бета-расхождение, включая, конечно, норму Фробениуса ($\beta=2$), (обобщенная) расходимость Кульбака-Лейблера ($\beta=1$) и расхождения Итакура-Сайто ($\beta=0$). Обратите внимание, что для $\beta \in (1; 2)$, решатель «mu» значительно быстрее, чем для других значений $\beta$. Также обратите внимание, что с отрицательным знаком (или 0, т. Е. «Итакура-сайто») $\beta$, входная матрица не может содержать нулевые значения.
Решающая программа cd может оптимизировать только норму Фробениуса. Из-за лежащей в основе невыпуклости NMF разные решатели могут сходиться к разным минимумам, даже при оптимизации одной и той же функции расстояния.
NMF лучше всего использовать с fit_transform методом, который возвращает матрицу $W$. Матрица $H$ сохраняется в подобранной модели в components_ атрибуте; метод transform разложит новую матрицу $X_{new}$ на основе этих сохраненных компонентов:
>>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]]) >>> from sklearn.decomposition import NMF >>> model = NMF(n_components=2, init='random', random_state=0) >>> W = model.fit_transform(X) >>> H = model.components_ >>> X_new = np.array([[1, 0], [1, 6.1], [1, 0], [1, 4], [3.2, 1], [0, 4]]) >>> W_new = model.transform(X_new)
Примеры:
Рекомендации:
- «Изучение частей объектов с помощью неотрицательной матричной факторизации» Д. Ли, С. Сын, 1999
- «Неотрицательная матричная факторизация с ограничениями разреженности» П. Хойер, 2004 г.
- «Инициализация на основе SVD: преимущество для неотрицательной матричной факторизации» К. Буцидис, Э. Галлопулос, 2008 г.
- «Быстрые локальные алгоритмы для крупномасштабных неотрицательных матричных и тензорных факторизаций». А. Цихоцкий, А. Фан, 2009 г.
- «Алгоритмы факторизации неотрицательной матрицы с бета-дивергенцией» К. Февот, Дж. Идье, 2011
2.5.7. Скрытое распределение Дирихле (LDA)
Скрытое распределение Дирихле — это генеративная вероятностная модель для коллекций дискретных наборов данных, таких как текстовые корпуса. Это также тематическая модель, которая используется для обнаружения абстрактных тем из коллекции документов.
Графическая модель LDA представляет собой трехуровневую генеративную модель:

Обратите внимание на обозначения, представленные в графической модели выше, которую можно найти у Hoffman et al. (2013):
- Корпус представляет собой собрание $D$ документы.
- Документ — это последовательность $N$ слова.
- Есть $K$ темы в корпусе.
- Прямоугольники представляют повторную выборку
В графической модели каждый узел является случайной величиной и играет роль в процессе генерации. Заштрихованный узел указывает наблюдаемую переменную, а незатененный узел указывает скрытую (скрытую) переменную. В этом случае слова в корпусе — единственные данные, которые мы наблюдаем. Скрытые переменные определяют случайное сочетание тем в корпусе и распределение слов в документах. Цель LDA — использовать наблюдаемые слова для определения скрытой структуры темы.
При моделировании корпусов текстов модель предполагает следующий процесс генерации корпуса с $D$ документы и $K$ темы, с $K$ соответствует n_components в API:
- По каждой теме $k \in K$, рисовать $\beta_k \sim\mathrm{Dirichlet}(\eta)$. Это обеспечивает распределение по словам, то есть вероятность того, что слово появится в теме $k$. $\eta$ соответствует
topic_word_prior. - Для каждого документа $d \in D$, нарисуйте пропорции темы $\theta_d \sim \mathrm{Dirichlet}(\alpha)$. αсоответствует
doc_topic_prior. - За каждое слово $i$ в документе $d$:
- Нарисуйте задание по теме $z_{di} \sim \mathrm{Multinomial}(\theta_d)$
- Нарисуйте наблюдаемое слово $w_{ij} \sim \mathrm{Multinomial}(\beta_{z_{di}})$
Для оценки параметров апостериорное распределение:
$$p(z, \theta, \beta |w, \alpha, \eta) = \frac{p(z, \theta, \beta|\alpha, \eta)}{p(w|\alpha, \eta)}$$
Поскольку апостериор неразрешим, вариационный байесовский метод использует более простое распределение $q(z,\theta,\beta | \lambda, \phi, \gamma)$ чтобы аппроксимировать его, и эти вариационные параметры $\lambda, \phi, \gamma$ оптимизированы для максимизации нижней границы доказательств (ELBO):
$$\log\: P(w | \alpha, \eta) \geq L(w,\phi,\gamma,\lambda) \overset{\triangle}{=} E_{q}[\log\:p(w,z,\theta,\beta|\alpha,\eta)] — E_{q}[\log\:q(z, \theta, \beta)]$$
Максимизация ELBO эквивалентна минимизации расхождения Кульбака-Лейблера (KL) между $q(z,\theta,\beta)$ и истинный задний $p(z, \theta, \beta |w, \alpha, \eta)$.
LatentDirichletAllocation реализует онлайн-вариационный алгоритм Байеса и поддерживает как онлайн-методы, так и методы пакетного обновления. В то время как пакетный метод обновляет вариационные переменные после каждого полного прохождения данных, онлайн-метод обновляет вариационные переменные из точек данных мини-пакета.
Примечание
Хотя онлайн-метод гарантированно сходится к локальной оптимальной точке, качество оптимальной точки и скорость сходимости могут зависеть от размера мини-пакета и атрибутов, связанных с настройкой скорости обучения.
При LatentDirichletAllocation применении к матрице «документ-термин» матрица будет разложена на матрицу «тема-термин» и матрицу «документ-тема». В то время как матрица «тема-термин» хранится как components_ в модели, матрица «документ-тема» может быть рассчитана с помощью transform метода.
LatentDirichletAllocation также реализует partial_fit метод. Это используется, когда данные могут быть получены последовательно.
Рекомендации:
- «Скрытое распределение Дирихле» Д. Блей, А. Нг, М. Джордан, 2003 г.
- «Онлайн-обучение для скрытого распределения Дирихле» М. Хоффман, Д. Блей, Ф. Бах, 2010 г.
- «Стохастический вариационный вывод» М. Хоффман, Д. Блей, К. Ван, Дж. Пейсли, 2013 г.
- «Критерий варимакс для аналитического вращения в факторном анализе» Х. Ф. Кайзер, 1958
См. Также Уменьшение размерности для уменьшения размерности с помощью анализа компонентов окружения.