8.2. Вычислительная производительность ¶
Для некоторых приложений производительность (в основном задержка и пропускная способность во время прогнозирования) оценщиков имеет решающее значение. Также может быть интересно рассмотреть пропускную способность обучения, но это часто менее важно в производственной установке (где это часто происходит в автономном режиме).
Мы рассмотрим здесь порядки величин, которые вы можете ожидать от ряда оценщиков scikit-learn в разных контекстах, и дадим несколько советов и приемов для преодоления узких мест в производительности.
Задержка прогнозирования измеряется как прошедшее время, необходимое для прогнозирования (например, в микросекундах). Задержка часто рассматривается как распределение, и инженеры по эксплуатации часто сосредотачиваются на задержке в данном процентиле этого распределения (например, 90 процентиле).
Пропускная способность прогнозирования определяется как количество прогнозов, которые программное обеспечение может доставить за заданный промежуток времени (например, в прогнозах в секунду).
Важным аспектом оптимизации производительности также является то, что это может снизить точность прогнозирования. Действительно, более простые модели (например, линейные вместо нелинейных или с меньшим количеством параметров) часто работают быстрее, но не всегда могут учитывать те же точные свойства данных, что и более сложные.
8.2.1. Задержка предсказания
Одна из наиболее очевидных проблем, которые могут возникнуть при использовании / выборе инструментария машинного обучения, — это задержка, с которой можно делать прогнозы в производственной среде.
Основными факторами, влияющими на задержку предсказания, являются:
- Количество функций
- Представление входных данных и разреженность
- Сложность модели
- Извлечение признаков
Последним важным параметром также является возможность делать прогнозы в массовом или однократном режиме.
8.2.1.1. Массовый или атомарный режим
В общем, выполнение массовых прогнозов (много экземпляров одновременно) более эффективно по ряду причин (предсказуемость ветвления, кэш ЦП, оптимизация библиотек линейной алгебры и т. д.). Здесь мы видим в настройке с несколькими функциями, что независимо от выбора оценщика объемный режим всегда быстрее, а для некоторых из них на 1-2 порядка:
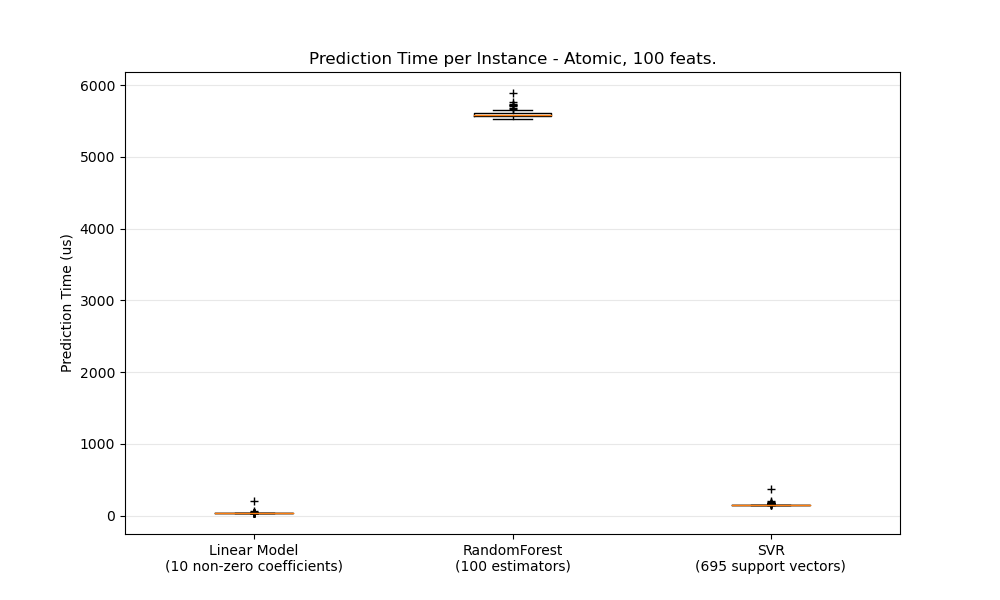
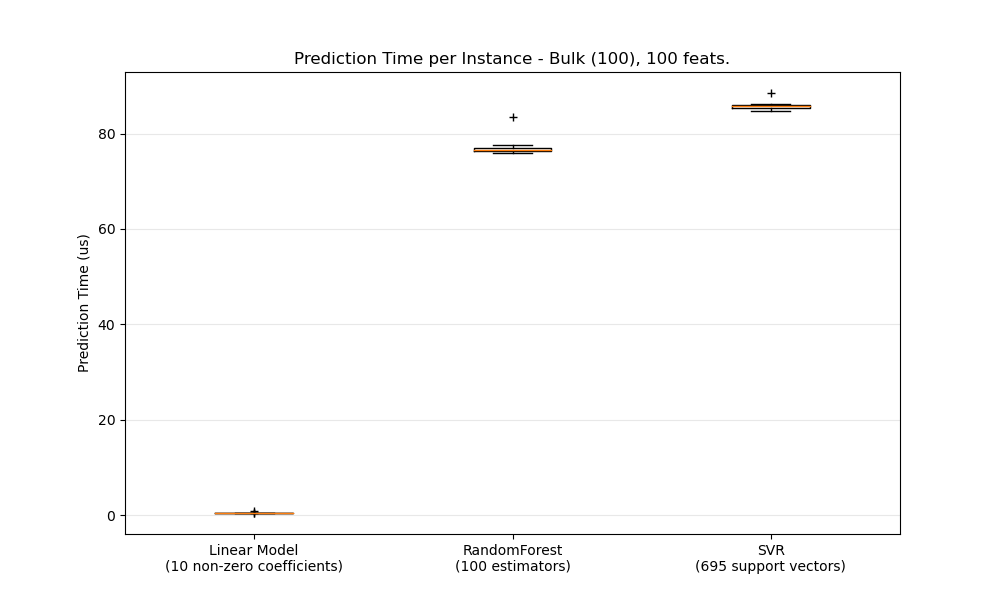
Чтобы сравнить различные оценщики для вашего случая, вы можете просто изменить n_featuresпараметр в этом примере: Prediction Latency . Это должно дать вам оценку порядка величины задержки предсказания.
8.2.1.2. Настройка Scikit-learn для снижения накладных расходов на проверку
Scikit-learn выполняет некоторую проверку данных, что увеличивает накладные расходы на вызов predict и аналогичные функции. В частности, проверка того, что функции являются конечными (не NaN или бесконечными), включает в себя полный проход по данным. Если вы уверены, что ваши данные приемлемы, вы можете подавить проверку на конечность, установив для переменной среды SKLEARN_ASSUME_FINITE непустую строку перед импортом scikit-learn или настроив ее в Python с помощью set_config. Для большего контроля, чем эти глобальные настройки, a config_context позволяет вам установить эту конфигурацию в указанном контексте:
>>> import sklearn >>> with sklearn.config_context(assume_finite=True): ... pass # do learning/prediction here with reduced validation
Обратите внимание, что это повлияет на все варианты использования assert_all_finite в контексте.
8.2.1.3. Влияние количества функций
Очевидно, что с увеличением количества функций увеличивается и потребление памяти в каждом примере. Действительно, для матрицы $M$ экземпляры с $N$ особенности, космическая сложность в $O(NM)$. С точки зрения вычислений это также означает, что количество основных операций (например, умножения векторно-матричных произведений в линейных моделях) также увеличивается. Вот график эволюции задержки прогнозирования в зависимости от количества функций:
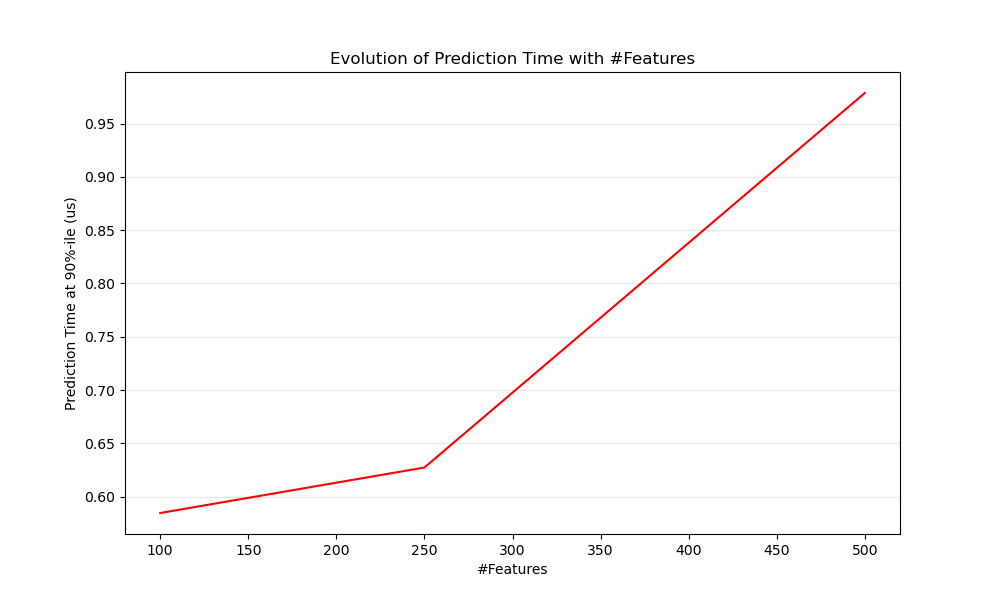
В целом вы можете ожидать, что время прогнозирования будет увеличиваться, по крайней мере, линейно с количеством функций (нелинейные случаи могут возникать в зависимости от объема глобальной памяти и оценки).
8.2.1.4. Влияние представления входных данных
Scipy предоставляет разреженные матричные структуры данных, оптимизированные для хранения разреженных данных. Основная особенность разреженных форматов заключается в том, что вы не храните нули, поэтому, если ваши данные разрежены, вы используете гораздо меньше памяти. Ненулевое значение в разреженном ( CSR или CSC ) представлении займет в среднем только одну 32-битную целочисленную позицию + 64-битное значение с плавающей запятой + дополнительные 32 бита на строку или столбец в матрице. Использование разреженных входных данных в плотной (или разреженной) линейной модели может значительно ускорить прогнозирование, поскольку только ненулевые характеристики влияют на скалярное произведение и, следовательно, на прогнозы модели. Следовательно, если у вас есть 100 ненулевых в пространстве измерений 1e6, вам нужно только 100 операций умножения и сложения вместо 1e6.
Однако при вычислении плотного представления могут использоваться высоко оптимизированные векторные операции и многопоточность в BLAS, что приводит к меньшему количеству промахов в кэше ЦП. Таким образом, разреженность обычно должна быть довольно высокой (максимум 10% ненулевых, проверяемых в зависимости от оборудования), чтобы разреженное входное представление было быстрее, чем плотное входное представление на машине с множеством процессоров и оптимизированной реализацией BLAS.
Вот пример кода для проверки разреженности вашего ввода:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))Как правило, вы можете принять во внимание, что если коэффициент разреженности превышает 90%, вы, вероятно, сможете извлечь выгоду из разреженных форматов. Обратитесь к документации по форматам разреженных матриц Scipy для получения дополнительной информации о том, как создавать (или преобразовывать ваши данные) в форматы разреженных матриц. Большая часть времени CSRи CSCформаты работают лучше.
8.2.1.5. Влияние сложности модели
Вообще говоря, когда сложность модели увеличивается, прогнозируемая мощность и задержка должны увеличиваться. Повышение предсказательной способности обычно интересно, но для многих приложений лучше не увеличивать слишком сильно задержку предсказания. Теперь мы рассмотрим эту идею для разных семейств контролируемых моделей.
Для sklearn.linear_model (например, Lasso, ElasticNet, SGDClassifier / Regressor, Ridge & RidgeClassifier, PassiveAggressiveClassifier / Regressor, LinearSVC, LogisticRegression…) функция принятия решения, которая применяется во время прогнозирования, такая же (точечный продукт), поэтому задержка должна быть эквивалентной.
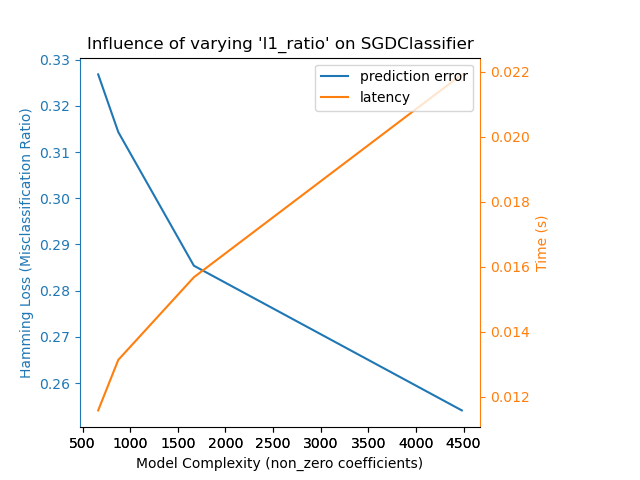
Вот пример использования SGDClassifier со elasticnet штрафом. Сила регуляризации глобально контролируется alpha параметром. При достаточно высоком alpha значении можно затем увеличить l1_ratio параметр, elasticnet чтобы обеспечить различные уровни разреженности в коэффициентах модели. Более высокая разреженность здесь интерпретируется как меньшая сложность модели, поскольку нам нужно меньше коэффициентов для ее полного описания. Конечно, разреженность, в свою очередь, влияет на время прогнозирования, поскольку разреженное скалярное произведение требует времени, примерно пропорционального количеству ненулевых коэффициентов.
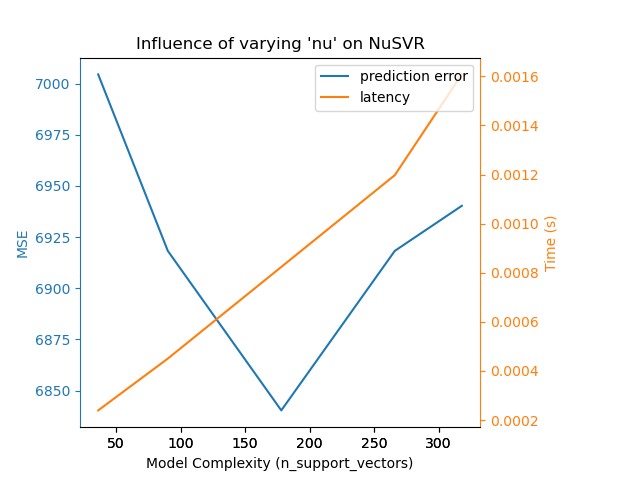
Для sklearn.svm семейства алгоритмов с нелинейным ядром задержка связана с количеством опорных векторов (чем меньше, тем быстрее). Задержка и пропускная способность должны (асимптотически) расти линейно с увеличением числа опорных векторов в модели SVC или SVR. Ядро также будет влиять на задержку, поскольку оно используется для вычисления проекции входного вектора один раз для каждого вектора поддержки. На следующем графике nu параметр NuSVR был использован для влияния на количество опорных векторов.
Для sklearn.ensemble деревьев (например, RandomForest, GBT, ExtraTrees и т. Д.) Количество деревьев и их глубина играют наиболее важную роль. Задержка и пропускная способность должны линейно масштабироваться с количеством деревьев. В этом случае мы использовали напрямую n_estimators параметр GradientBoostingRegressor.
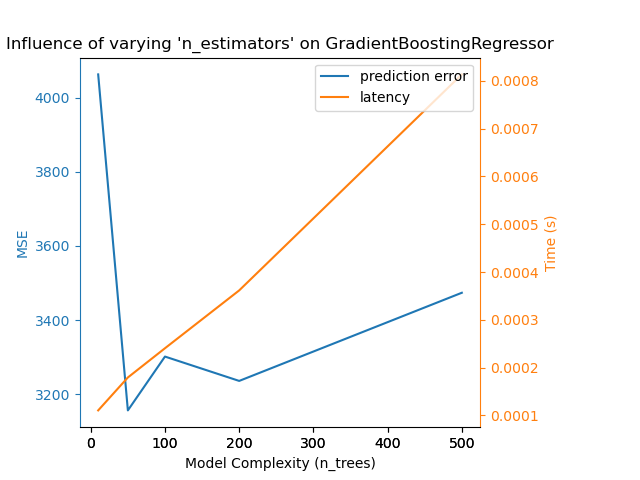
В любом случае имейте в виду, что уменьшение сложности модели может снизить точность, как упоминалось выше. Например, проблема с нелинейным разделением может быть решена с помощью быстрой линейной модели, но мощность прогнозирования, скорее всего, пострадает в процессе.
8.2.1.6. Задержка при извлечении функций
Большинство моделей scikit-learn обычно довольно быстрые, поскольку они реализованы либо с помощью скомпилированных расширений Cython, либо с помощью оптимизированных вычислительных библиотек. С другой стороны, во многих реальных приложениях процесс извлечения признаков (то есть преобразование необработанных данных, таких как строки базы данных или сетевые пакеты в несколько массивов), управляет общим временем прогнозирования. Например, в задаче классификации текста Reuters вся подготовка (чтение и анализ файлов SGML, разметка текста и хеширование его в общее векторное пространство) занимает от 100 до 500 раз больше времени, чем фактический код прогнозирования, в зависимости от выбранной модели.
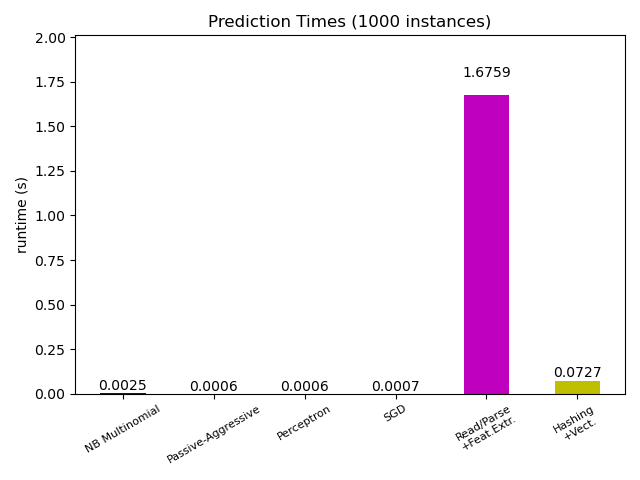
Поэтому во многих случаях рекомендуется тщательно рассчитывать время и профилировать код извлечения функций, поскольку это может быть хорошим местом для начала оптимизации, когда общая задержка слишком медленная для вашего приложения.
8.2.2. Прогнозирование пропускной способности
Еще одна важная метрика, на которую следует обратить внимание при определении размеров производственных систем, — это пропускная способность, то есть количество прогнозов, которые вы можете сделать за заданный промежуток времени. Вот эталонный тест из примера Prediction Latency, который измеряет эту величину для ряда оценщиков синтетических данных:
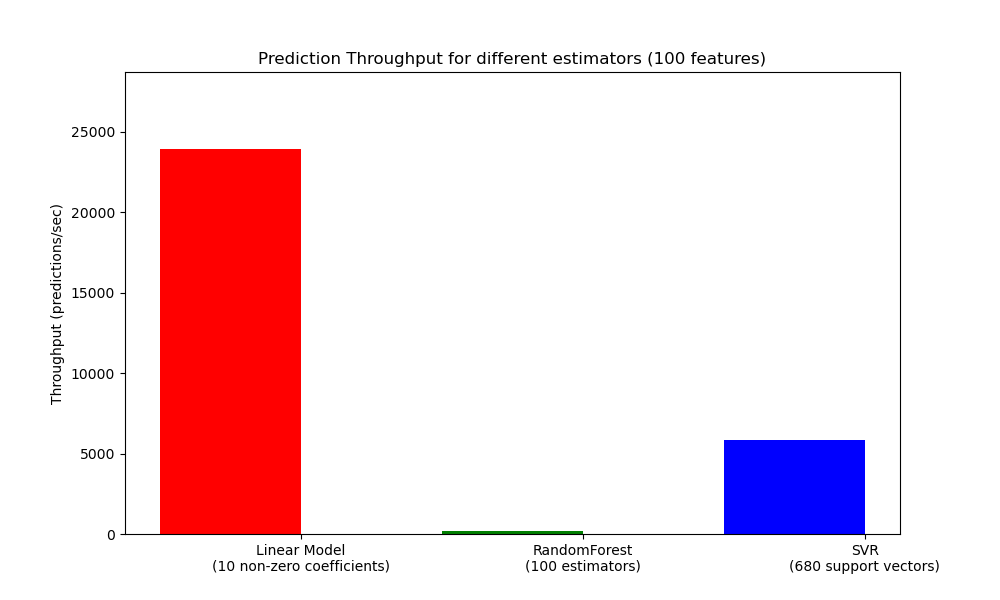
Эти показатели достигаются за один процесс. Очевидный способ увеличить пропускную способность вашего приложения — создать дополнительные экземпляры (обычно процессы в Python из-за GIL ), которые используют одну и ту же модель. Можно также добавить машины для распределения нагрузки. Однако подробное объяснение того, как этого добиться, выходит за рамки данной документации.
8.2.3. Советы и хитрости
8.2.3.1. Библиотеки линейной алгебры
Поскольку scikit-learn сильно зависит от Numpy / Scipy и линейной алгебры в целом, имеет смысл явно позаботиться о версиях этих библиотек. По сути, вы должны убедиться, что Numpy построен с использованием оптимизированной библиотеки BLAS / LAPACK .
Не все модели выигрывают от оптимизированных реализаций BLAS и Lapack. Для моделей экземпляра на основе (рандомизированы) деревья решений , как правило , не зависят от BLAS вызовов в своих внутренних петлях, и не ядро SVMs ( SVC, SVR, NuSVC, NuSVR). С другой стороны, линейная модель, реализованная с вызовом BLAS DGEMM (через numpy.dot), обычно значительно выигрывает от настроенной реализации BLAS и приводит к ускорению на порядки по сравнению с неоптимизированным BLAS.
Вы можете отобразить реализацию BLAS / LAPACK, используемую вашей установкой NumPy / SciPy / scikit-learn, с помощью следующих команд:
from numpy.distutils.system_info import get_info
print(get_info('blas_opt'))
print(get_info('lapack_opt'))Оптимизированные реализации BLAS / LAPACK включают:
- Атлас (требуется настройка оборудования путем перестройки на целевой машине)
- OpenBLAS
- MKL
- Фреймворки Apple Accelerate и vecLib (только OSX)
Дополнительную информацию можно найти на странице установки Scipy и в этом сообщении в блоге Даниэля Нури, в котором есть несколько хороших пошаговых инструкций по установке для Debian / Ubuntu.
8.2.3.2. Ограничение рабочей памяти
Некоторые вычисления, реализованные с использованием стандартных векторных операций numpy, включают использование большого количества временной памяти. Это может потенциально исчерпать системную память. Если вычисления могут выполняться в блоках с фиксированной памятью, мы пытаемся сделать это и позволяем пользователю указывать максимальный размер этой рабочей памяти (по умолчанию 1 ГБ) с помощью set_config или config_context. Ниже предлагается ограничить временную рабочую память до 128 МБ:
>>> import sklearn >>> with sklearn.config_context(working_memory=128): ... pass # do chunked work here
Примером разбитой на части операции, придерживающейся этого параметра, является то pairwise_distances_chunked, что облегчает вычисление построчных сокращений попарной матрицы расстояний.
8.2.3.3. Сжатие модели
Сжатие моделей в scikit-learn пока касается только линейных моделей. В данном контексте это означает, что мы хотим контролировать разреженность модели (то есть количество ненулевых координат в векторах модели). Как правило, рекомендуется сочетать разреженность модели с разреженным представлением входных данных.
Вот пример кода, который иллюстрирует использование sparsify() метода:
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25) clf.fit(X_train, y_train).sparsify() clf.predict(X_test)
В этом примере мы предпочитаем elasticnet штраф, поскольку он часто является хорошим компромиссом между компактностью модели и мощностью прогнозирования. Можно также дополнительно настроить l1_ratio параметр (в сочетании с силой регуляризации alpha), чтобы контролировать этот компромисс.
Типичный тест синтетических данных дает снижение задержки> 30%, когда и модель, и входные данные являются разреженными (с соотношением ненулевых коэффициентов 0,000024 и 0,027400 соответственно). Ваш пробег может варьироваться в зависимости от разреженности и размера ваших данных и модели. Кроме того, разрежение может быть очень полезным для уменьшения использования памяти прогнозными моделями, развернутыми на производственных серверах.
8.2.3.4. Изменение формы модели
Изменение формы модели заключается в выборе только части доступных функций для соответствия модели. Другими словами, если модель отбрасывает функции на этапе обучения, мы можем удалить их из входных данных. Это дает несколько преимуществ. Во-первых, это уменьшает накладные расходы на память (и, следовательно, время) самой модели. Это также позволяет отказаться от компонентов явного выбора функций в конвейере, если мы знаем, какие функции следует сохранить из предыдущего запуска. Наконец, это может помочь сократить время обработки и использование операций ввода-вывода в восходящем направлении на уровнях доступа к данным и извлечения функций, не собирая и не создавая элементы, которые отбрасываются моделью. Например, если необработанные данные поступают из базы данных, это может позволить писать более простые и быстрые запросы или уменьшать использование ввода-вывода, заставляя запросы возвращать более легкие записи. В данный момент,изменение формы необходимо выполнять вручную в scikit-learn. В случае разреженного ввода (особенно в CSR формат), как правило, достаточно не генерировать соответствующие функции, оставив их столбцы пустыми.