3.2. Настройка гиперпараметров оценщика ¶
Гиперпараметры — это параметры, которые не изучаются напрямую в оценщиках. В scikit-learn они передаются в качестве аргументов конструктору классов оценщика. Типичные примеры включают C, kernelи gamma для поддержки Вектор классификатором, alpha для Лассо и т.д.
Можно и рекомендуется поискать в пространстве гиперпараметров лучший результат перекрестной проверки .
Таким образом можно оптимизировать любой параметр, предоставленный при построении оценщика. В частности, чтобы найти имена и текущие значения всех параметров для данного оценщика, используйте:
estimator.get_params()
Поиск состоит из:
- оценщик (регрессор или классификатор, например
sklearn.svm.SVC()); - пространство параметров;
- метод поиска или отбора кандидатов;
- схема перекрестной проверки; а также
- оценка функции.
В scikit-learn предусмотрены два общих подхода к поиску параметров: для заданных значений GridSearchCV исчерпывающе рассматриваются все комбинации параметров, а RandomizedSearchCV можно выбрать заданное количество кандидатов из пространства параметров с указанным распределением. У обоих этих инструментов есть последовательные двойники HalvingGridSearchCV и HalvingRandomSearchCV, что может быть намного быстрее при поиске хорошей комбинации параметров.
После описания этих инструментов мы подробно описываем лучшую практику, применимый к этим подходам. Некоторые модели допускают специализированные, эффективные стратегии поиска параметров, описанные в разделе Альтернативы поиску параметров методом грубой силы .
Обратите внимание, что обычно небольшое подмножество этих параметров может иметь большое влияние на производительность прогнозирования или вычислений модели, в то время как для других можно оставить значения по умолчанию. Рекомендуется прочитать строку документации класса оценщика, чтобы лучше понять их ожидаемое поведение, возможно, прочитав прилагаемую ссылку на литературу.
3.2.1. Исчерпывающий поиск по сетке
Поиск по сетке, предоставляемый с помощью, GridSearchCV исчерпывающе генерирует кандидатов из сетки значений параметров, указанных в param_grid параметре. Например, следующее param_grid:
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]указывает, что должны быть исследованы две сетки: одна с линейным ядром и значениями C в [1, 10, 100, 1000], а вторая с ядром RBF и перекрестным произведением значений C в диапазоне [1, 10 , 100, 1000] и значения гаммы в [0,001, 0,0001].
В GridSearchCV экземпляре реализует обычный API оценки: когда «уместно» его на наборе данных всех возможные комбинации значений параметров оцениваются и наилучшее сочетание сохраняются.
Примеры:
- См. Раздел « Оценка параметров с использованием поиска по сетке с перекрестной проверкой», где приведен пример вычисления поиска по сетке для набора данных цифр.
- См. Пример конвейера для извлечения и оценки текстовых признаков, где приведен пример параметров связывания Grid Search из экстрактора признаков текстовых документов (векторизатор подсчета n-граммов и преобразователь TF-IDF) с классификатором (здесь линейная SVM, обученная с помощью SGD с любой эластичной сеткой). или штраф L2) с использованием
pipeline.Pipelineэкземпляра. - См. Раздел Вложенная и невложенная перекрестная проверка для примера поиска по сетке в цикле перекрестной проверки для набора данных радужной оболочки глаза. Это лучший способ оценки производительности модели с поиском по сетке.
- См. Демонстрацию
GridSearchCVоценки нескольких показателей на cross_val_score и GridSearchCV для примера использования для одновременной оценки нескольких показателей. - См. Раздел « Сложность модели баланса и оценка с перекрестной проверкой» для примера использования
refit=callableинтерфейса вGridSearchCV. Пример показывает, как этот интерфейс добавляет определенную гибкость в определении «наилучшего» оценщика. Этот интерфейс также можно использовать для оценки нескольких показателей. - См. В разделе Статистическое сравнение моделей с использованием поиска по сетке пример того, как проводить статистическое сравнение выходных данных
GridSearchCV.
3.2.2. Оптимизация случайных параметров
Хотя использование сетки настроек параметров в настоящее время является наиболее широко используемым методом оптимизации параметров, другие методы поиска имеют более благоприятные свойства. RandomizedSearchCV реализует рандомизированный поиск по параметрам, где каждый параметр выбирается из распределения по возможным значениям параметров. У этого есть два основных преимущества перед исчерпывающим поиском:
- Бюджет можно выбрать независимо от количества параметров и возможных значений.
- Добавление параметров, не влияющих на производительность, не снижает эффективность.
Указание того, как следует выбирать параметры, выполняется с помощью словаря, очень похожего на указание параметров для GridSearchCV. Кроме того, с помощью n_iter параметра указывается бюджет вычислений, представляющий собой количество выбранных кандидатов или итераций выборки . Для каждого параметра можно указать либо распределение по возможным значениям, либо список дискретных вариантов (которые будут выбираться равномерно):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}В этом примере используется scipy.stats модуль, который содержит много полезных распределений для выборки параметров, такие как expon, gamma, uniform или randint.
В принципе, можно передать любую функцию, которая предоставляет rvs метод (случайной выборки) для выборки значения. Вызов rvs функции должен предоставлять независимые случайные выборки из возможных значений параметров при последовательных вызовах.
Предупреждение
Распределения scipy.stats до версии scipy 0.16 не позволяют указывать случайное состояние. Вместо этого они используют глобальное случайное состояние numpy, которое можно засеять np.random.seed или установить с помощью np.random.set_state. Однако, начиная с scikit-learn 0.18, sklearn.model_selection модуль устанавливает случайное состояние, предоставляемое пользователем, если также доступен scipy> = 0.16.
Для непрерывных параметров, таких как C выше, важно указать непрерывное распределение, чтобы в полной мере воспользоваться преимуществами рандомизации. Таким образом, увеличение n_iter всегда приведет к более точному поиску.
Непрерывная логарифмически однородная случайная величина доступна через loguniform. Это непрерывная версия параметров, разделенных журналами. Например, чтобы указать C выше loguniform(1, 100), можно использовать вместо [1, 10, 100] или SciPy .np.logspace(0, 2, num=1000). Это псевдоним stats.reciprocal
Отражая приведенный выше пример в поиске по сетке, мы можем указать непрерывную случайную переменную, которая равномерно распределена между 1e0 и 1e3:
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}Примеры:
- При сравнении рандомизированного поиска и поиска по сетке для оценки гиперпараметров сравнивается использование и эффективность рандомизированного поиска и поиска по сетке.
Рекомендации:
- Бергстра Дж. И Бенжио Ю., Случайный поиск для оптимизации гиперпараметров, Журнал исследований в области машинного обучения (2012).
3.2.3. Поиск оптимальных параметров с последовательным делением пополам
Scikit-узнать также предоставляет HalvingGridSearchCV и HalvingRandomSearchCV оценки , которые могут быть использованы для поиска пространства параметров с помощью последовательного деления пополам (Источники 1 — 2). Последовательное сокращение вдвое (SH) похоже на турнир среди возможных комбинаций параметров. SH — это итеративный процесс выбора, в котором все кандидаты (комбинации параметров) оцениваются с небольшим количеством ресурсов на первой итерации. Только некоторые из этих кандидатов выбираются для следующей итерации, для которой будет выделено больше ресурсов. Для настройки параметров ресурс обычно представляет собой количество обучающих выборок, но это также может быть произвольный числовой параметр, например, n_estimators в случайном лесу.
Как показано на рисунке ниже, только часть кандидатов «доживает» до последней итерации. Это кандидаты, которые стабильно входят в число лучших кандидатов на всех итерациях. На каждой итерации на каждого кандидата выделяется все большее количество ресурсов, здесь количество выборок.
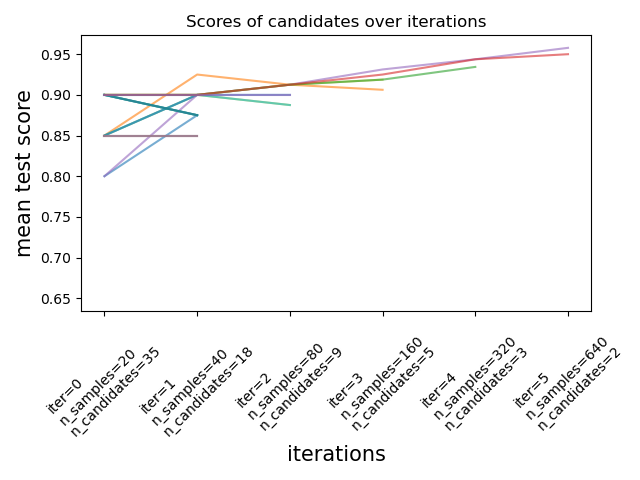
Здесь мы кратко описываем основные параметры, но каждый параметр и их взаимодействие более подробно описаны в разделах ниже. Параметр factor (> 1) контролирует скорость роста ресурсов и скорость уменьшения количества кандидатов. На каждой итерации количество ресурсов каждого кандидата умножается на, factor а количество кандидатов делится на тот же коэффициент. Наряду с resource и min_resources, factor является наиболее важным параметром для управления поиском в нашей реализации, хотя значение 3 , как правило , работает хорошо. factor эффективно контролирует количество итераций в HalvingGridSearchCV и количество кандидатов (по умолчанию) и итераций в HalvingRandomSearchCV. aggressive_elimination=True также можно использовать, если количество доступных ресурсов невелико. Больше контроля доступно через настройку min_resources параметра.
Эти оценщики все еще являются экспериментальными : их прогнозы и их API могут измениться без какого-либо цикла устаревания. Чтобы использовать их, вам необходимо явно импортировать enable_halving_search_cv:
>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> # now you can import normally from model_selection >>> from sklearn.model_selection import HalvingGridSearchCV >>> from sklearn.model_selection import HalvingRandomSearchCV
Примеры:
3.2.3.1. Выбор min_resources и количество кандидатов
Кроме того factor, два основных параметра, которые влияют на поведение последовательного поиска пополам, — это min_resources параметр и количество оцениваемых кандидатов (или комбинаций параметров). min_resources — количество ресурсов, выделенных на первой итерации для каждого кандидата. Количество кандидатов указывается непосредственно в HalvingRandomSearchCV, и определяется param_grid параметром HalvingGridSearchCV.
Рассмотрим случай, когда ресурс — это количество выборок, а у нас есть 1000 выборок. Теоретически, с min_resources=10 и factor=2, мы способны работать более 7 итераций со следующим количеством образцов: [10, 20, 40, 80, 160, 320, 640].
Но в зависимости от количества кандидатов мы можем запустить менее 7 итераций: если мы начнем с небольшого количества кандидатов, последняя итерация может использовать менее 640 образцов, что означает использование не всех доступных ресурсов (образцов). Например, если мы начинаем с 5 кандидатов, нам нужны только 2 итерации: 5 кандидатов для первой итерации, затем 5 // 2 = 2 кандидаты на второй итерации, после чего мы знаем, какой кандидат работает лучше всего (поэтому нам не нужен третий). Мы будем использовать не более 20 образцов, что является пустой тратой, поскольку в нашем распоряжении 1000 образцов. С другой стороны, если мы начнем с высокого количества кандидатов, мы можем получить много кандидатов на последней итерации, что не всегда может быть идеальным: это означает, что многие кандидаты будут работать с полными ресурсами, в основном сокращая процедуру до стандартного поиска.
В случае HalvingRandomSearchCV, количество кандидатов устанавливается по умолчанию таким образом, чтобы последняя итерация использовала как можно больше доступных ресурсов. Для HalvingGridSearchCV количество кандидатов определяется param_grid параметром. Изменение значения min_resourcesповлияет на количество возможных итераций и, как следствие, также повлияет на идеальное количество кандидатов.
Еще одно соображение при выборе min_resources заключается в том, легко ли отличить хороших кандидатов от плохих при небольшом количестве ресурсов. Например, если вам нужно много образцов, чтобы различать хорошие и плохие параметры, рекомендуется высокое значение min_resources. С другой стороны, если различие очевидно даже при небольшом количестве выборок, тогда небольшое min_resources может быть предпочтительнее, поскольку это ускорит вычисление.
Обратите внимание, что в приведенном выше примере последняя итерация не использует максимальное количество доступных ресурсов: доступно 1000 выборок, но используется самое большее только 640. По умолчанию оба HalvingRandomSearchCV и HalvingGridSearchCV пытаются использовать как можно больше ресурсов на последней итерации, с ограничением, что это количество ресурсов должно быть кратным обоим min_resourcesи factor(это ограничение будет понятно в следующем разделе). HalvingRandomSearchCV достигает этого путем отбора правильного количества кандидатов, в то время как HalvingGridSearchCV достигается это путем правильной настройки min_resources. См. Подробности в разделе « Исчерпание доступных ресурсов» .
3.2.3.2. Количество ресурса и количество кандидатов на каждой итерации
На любой итерации i каждому кандидату выделяется определенное количество ресурсов, которое мы обозначаем n_resources_i. Это количество контролируется параметрами factor и min_resources следующим образом ( factor строго больше 1):
n_resources_i = factor**i * min_resources,
или эквивалентно:
n_resources_{i+1} = n_resources_i * factorгде min_resources == n_resources_0 — количество ресурсов, использованных на первой итерации. factor также определяет пропорции кандидатов, которые будут выбраны для следующей итерации:
n_candidates_i = n_candidates // (factor ** i)
или эквивалентно:
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factorИтак, в первой итерации мы используем время min_resources ресурсов n_candidates. Во второй итерации мы используем min_resources * factor ресурсов n_candidates // factor. Третий снова умножает ресурсы на кандидата и делит количество кандидатов. Этот процесс останавливается, когда достигается максимальный объем ресурсов для каждого кандидата или когда мы определили лучшего кандидата. Наилучший кандидат определяется на итерации, на которой оценивается factor или меньшее количество кандидатов (см. Пояснение ниже).
Вот пример с min_resources=3 и factor=2, начиная с 70 кандидатов:
| n_resources_i | n_candidates_i |
| 3 (= min_resources) | 70 (= n_candidates) |
| 3 * 2 = 6 | 70 // 2 = 35 |
| 6 * 2 = 12 | 35 // 2 = 17 |
| 12 * 2 = 24 | 17 // 2 = 8 |
| 24 * 2 = 48 | 8 // 2 = 4 |
| 48 * 2 = 96 | 4 // 2 = 2 |
Отметим, что:
- процесс останавливается на первой итерации, которая оценивает
factor=2кандидатов: лучший кандидат — лучший из этих двух кандидатов. Нет необходимости запускать дополнительную итерацию, поскольку она будет оценивать только одного кандидата (а именно лучшего, которого мы уже определили). По этой причине, как правило, мы хотим, чтобы на последней итерации выполнялось не большеfactorкандидатов. Если последняя итерация оценивает больше, чемfactorкандидатов, то эта последняя итерация сводится к обычному поиску (как вRandomizedSearchCVилиGridSearchCV). - каждый
n_resources_iявляется кратным обоимfactorиmin_resources(что подтверждается его определением выше).
Количество ресурсов, используемых на каждой итерации, можно найти в n_resources_ атрибуте.
3.2.3.3. Выбор ресурса
По умолчанию ресурс определяется количеством образцов. То есть каждая итерация будет использовать увеличивающееся количество образцов для обучения. Однако вы можете вручную указать параметр, который будет использоваться в качестве ресурса с resource параметром. Вот пример, в котором ресурс определяется с точки зрения количества оценщиков случайного леса:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)Обратите внимание, что невозможно составить бюджет для параметра, который является частью сетки параметров.
3.2.3.4. Исчерпание имеющихся ресурсов
Как упоминалось выше, количество ресурсов, используемых на каждой итерации, зависит от min_resources параметра. Если у вас много доступных ресурсов, но вы начинаете с небольшого количества ресурсов, некоторые из них могут быть потрачены впустую (т. е. не использоваться):
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]Процесс поиска будет использовать не более 80 ресурсов, в то время как наше максимальное количество доступных ресурсов составляет n_samples=1000. Вот и есть .min_resources = r_0 = 20
По HalvingGridSearchCV умолчанию для min_resources параметра установлено значение «выхлоп». Это означает, что min_resources он автоматически устанавливается таким образом, что последняя итерация может использовать как можно больше ресурсов в пределах max_resources лимита:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5, ... factor=2, min_resources='exhaust').fit(X, y) >>> sh.n_resources_ [250, 500, 1000]
min_resources был здесь автоматически установлен на 250, что приводит к тому, что последняя итерация использует все ресурсы. Точное значение, которое используется, зависит от количества параметров кандидата, от max_resources и до factor.
Ведь HalvingRandomSearchCV исчерпание ресурсов можно осуществить двумя способами:
- установив
min_resources='exhaust', как и дляHalvingGridSearchCV; - установив
n_candidates='exhaust'.
Оба варианта являются взаимоисключающими: использование min_resources='exhaust' требует знания количества кандидатов, а симметрично — n_candidates='exhaust' знания min_resources.
В общем, исчерпание общего количества ресурсов приводит к лучшему окончательному параметру кандидата и требует немного больше времени.
3.2.3.5. Агрессивное устранение кандидатов
В идеале мы хотим, чтобы последняя итерация оценивала factor кандидатов (см. Количество ресурсов и количество кандидатов на каждой итерации ). Затем нам просто нужно выбрать лучший. Когда количество доступных ресурсов невелико по сравнению с количеством кандидатов, на последней итерации может потребоваться оценить больше, чем factor кандидатов:
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>>
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]Поскольку мы не можем использовать больше max_resources=40 ресурсов, процесс должен останавливаться на второй итерации, которая оценивает больше, чем factor=2 кандидатов.
Используя aggressive_elimination параметр, вы можете заставить процесс поиска закончить с меньшим количеством factor кандидатов на последней итерации. Для этого процесс удалит столько кандидатов, сколько необходимо, используя min_resources ресурсы:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5, ... factor=2, ... max_resources=40, ... aggressive_elimination=True, ... ).fit(X, y) >>> sh.n_resources_ [20, 20, 40] >>> sh.n_candidates_ [6, 3, 2]
Обратите внимание, что мы закончили с двумя кандидатами на последней итерации, так как мы исключили достаточное количество кандидатов во время первых итераций, используя n_resources = min_resources = 20.
3.2.3.6. Анализ результатов с cv_results_ атрибутом
Атрибут cv_results_ содержит полезную информацию для анализа результатов поиска. Его можно преобразовать в фрейм данных pandas с помощью df = pd.DataFrame(est.cv_results_). Атрибут cv_results из HalvingGridSearchCV и HalvingRandomSearchCV подобен GridSearchCV и RandomizedSearchCV с дополнительной информацией, связанной с последовательным процессом сокращения вдвое.
Вот пример с некоторыми столбцами (усеченного) фрейма данных:
| iter | n_resources | mean_test_score | параметры | |
| 0 | 0 | 125 | 0,983667 | {‘критерий’: ‘энтропия’, ‘max_depth’: нет, ‘max_features’: 9, ‘min_samples_split’: 5} |
| 1 | 0 | 125 | 0,983667 | {‘критерий’: ‘gini’, ‘max_depth’: нет, ‘max_features’: 8, ‘min_samples_split’: 7} |
| 2 | 0 | 125 | 0,983667 | {‘критерий’: ‘gini’, ‘max_depth’: нет, ‘max_features’: 10, ‘min_samples_split’: 10} |
| 3 | 0 | 125 | 0,983667 | {‘критерий’: ‘энтропия’, ‘max_depth’: нет, ‘max_features’: 6, ‘min_samples_split’: 6} |
| … | … | … | … | … |
| 15 | 2 | 500 | 0,951958 | {‘критерий’: ‘энтропия’, ‘max_depth’: нет, ‘max_features’: 9, ‘min_samples_split’: 10} |
| 16 | 2 | 500 | 0,947958 | {‘критерий’: ‘gini’, ‘max_depth’: нет, ‘max_features’: 10, ‘min_samples_split’: 10} |
| 17 | 2 | 500 | 0,951958 | {‘критерий’: ‘gini’, ‘max_depth’: нет, ‘max_features’: 10, ‘min_samples_split’: 4} |
| 18 | 3 | 1000 | 0,961009 | {‘критерий’: ‘энтропия’, ‘max_depth’: нет, ‘max_features’: 9, ‘min_samples_split’: 10} |
| 19 | 3 | 1000 | 0,955989 | {‘критерий’: ‘gini’, ‘max_depth’: нет, ‘max_features’: 10, ‘min_samples_split’: 4} |
Каждая строка соответствует заданной комбинации параметров (кандидату) и заданной итерации. Итерация указана в iter столбце. В n_resources столбце указано, сколько ресурсов было использовано.
В приведенном выше примере наилучшая комбинация параметров {‘criterion’: ‘entropy’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 10} заключается в том, что она достигла последней итерации (3) с наивысшим баллом:
Рекомендации:
- К. Джеймисон, А. Талвалкар, Нестохастическая идентификация наилучшей руки и оптимизация гиперпараметров , в сб. исследований в области машинного обучения, 2016 г.
- Л. Ли, К. Джеймисон, Г. ДеСальво, А. Ростамизаде, А. Талвалкар, Hyperband: новый бандитский подход к оптимизации гиперпараметров , in Machine Learning Research 18, 2018.
3.2.4. Советы по поиску параметров
3.2.4.1. Указание объективной метрики
По умолчанию поиск параметров использует score функцию оценщика для оценки настройки параметра. Это sklearn.metrics.accuracy_score для классификации и sklearn.metrics.r2_score для регрессии. Для некоторых приложений лучше подходят другие функции оценки (например, при несбалансированной классификации оценка точности часто неинформативна). Альтернативная функция оценки может быть указана с помощью scoring параметра большинства инструментов поиска параметров. Дополнительные сведения см. В разделе Параметр оценки: определение правил оценки модели .
3.2.4.2. Указание нескольких показателей для оценки
GridSearchCV и RandomizedSearchCV позволяют указать несколько показателей для scoring параметра.
Мультиметрическая оценка может быть указана либо в виде списка строк с предварительно определенными именами оценок, либо в виде словаря, сопоставляющего имя счетчика с функцией счетчика и / или предварительно определенное имя (имена) счетчика. Дополнительные сведения см. В разделе Использование множественной метрической оценки.
При указании нескольких метрик refit параметр должен быть установлен на метрику (строку), для которой best_params_ будет найден и использован для построения best_estimator_ всего набора данных. Если поиск не надо переоборудовать, ставим refit=False. Если оставить для восстановления значение по умолчанию, None это приведет к ошибке при использовании нескольких показателей.
См. Пример использования в демонстрации многомерной оценки cross_val_score и GridSearchCV .
HalvingRandomSearchCV и HalvingGridSearchCV не поддерживают мультиметрическую оценку.
3.2.4.3. Составные оценки и пространства параметров
GridSearchCV и RandomizedSearchCV позволяют искать более параметры композитных или вложенные оценки , такие как Pipeline, ColumnTransformer, VotingClassifier или CalibratedClassifierCV <estimator>__<parameter> синтаксис:
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... base_estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'base_estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(...),
param_grid={'base_estimator__max_depth': [2, 4, 6, 8]})В <estimator> данном случае это имя параметра вложенного оценщика base_estimator. Если метаоценка построена как набор оценщиков, как в pipeline.Pipeline, то <estimator> ссылается на имя оценщика, см. Вложенные параметры. На практике может быть несколько уровней вложенности:
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__base_estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)Пожалуйста, обратитесь к конвейеру: цепочки оценок для выполнения поиска параметров по конвейерам.
3.2.4.4. Выбор модели: разработка и оценка
Выбор модели путем оценки различных настроек параметров можно рассматривать как способ использования помеченных данных для «обучения» параметров сетки.
При оценке результирующей модели важно делать это на удерживаемых выборках, которые не были замечены в процессе поиска по сетке: рекомендуется разделить данные на набор для разработки (для передачи в GridSearchCV экземпляр) и набор для оценки вычислить показатели производительности.
Это можно сделать с помощью train_test_split служебной функции.
3.2.4.5. Параллелизм
Инструменты поиска параметров оценивают каждую комбинацию параметров для каждой свертки данных независимо. Вычисления могут выполняться параллельно с помощью ключевого слова n_jobs=-1. См. Подпись функции для более подробной информации, а также запись в глоссарии для n_jobs .
3.2.4.6. Отказоустойчивость
Некоторые настройки параметров могут привести к сбою fit одной или нескольких сверток данных. По умолчанию это приведет к сбою всего поиска, даже если некоторые настройки параметров могут быть полностью оценены. Установка error_score=0 (или =np.NaN) сделает процедуру устойчивой к такому отказу, выдаст предупреждение и установит счет для этой свертки на 0 (или NaN), но завершит поиск.
3.2.5. Альтернативы поиску параметров методом перебора
3.2.5.1. Перекрестная проверка модели
Некоторые модели могут подбирать данные для диапазона значений некоторого параметра почти так же эффективно, как подгонка оценки для одного значения параметра. Эту функцию можно использовать для более эффективной перекрестной проверки, используемой для выбора модели этого параметра.
Наиболее распространенным параметром, поддающимся этой стратегии, является параметр, кодирующий силу регуляризатора. В этом случае мы говорим, что вычисляем путь регуляризации (regularization path) оценки.
Вот список таких моделей:
linear_model.ElasticNetCV(*[, l1_ratio, …]) | Модель Elastic Net с итеративной подгонкой по пути регуляризации. |
linear_model.LarsCV(*[, fit_intercept, …]) | Перекрестная проверенная модель регрессии по наименьшему углу. |
linear_model.LassoCV(*[, eps, n_alphas, …]) | Линейная модель лассо с итеративной подгонкой по пути регуляризации. |
linear_model.LassoLarsCV(*[, fit_intercept, …]) | Лассо с перекрестной проверкой с использованием алгоритма LARS. |
linear_model.LogisticRegressionCV(*[, Cs, …]) | Классификатор логистической регрессии CV (он же логит, MaxEnt). |
linear_model.MultiTaskElasticNetCV(*[, …]) | Многозадачность L1 / L2 ElasticNet со встроенной перекрестной проверкой. |
linear_model.MultiTaskLassoCV(*[, eps, …]) | Многозадачная модель Лассо, обученная со смешанной нормой L1 / L2 в качестве регуляризатора. |
linear_model.OrthogonalMatchingPursuitCV(*) | Перекрестно проверенная модель ортогонального соответствия (OMP). |
linear_model.RidgeCV([alphas, …]) | Риджевая регрессия со встроенной перекрестной проверкой. |
linear_model.RidgeClassifierCV([alphas, …]) | Классификатор Ridge со встроенной перекрестной проверкой. |
3.2.5.2. Информационный критерий
Некоторые модели могут предлагать теоретико-информационную формулу в закрытой форме оптимальной оценки параметра регуляризации путем вычисления одного пути регуляризации (вместо нескольких при использовании перекрестной проверки).
Вот список моделей, использующих информационный критерий Акаике (AIC) или байесовский информационный критерий (BIC) для автоматического выбора модели:
linear_model.LassoLarsIC([criterion, …]) | Модель лассо соответствует Ларсу с использованием BIC или AIC для выбора модели |
3.2.5.3. Оценки вне сумки
При использовании методов ансамбля, основанных на упаковке, т. Е. Создании новых обучающих наборов с использованием выборки с заменой, часть обучающего набора остается неиспользованной. Для каждого классификатора в ансамбле не учитывается отдельная часть обучающей выборки.
Эту оставшуюся часть можно использовать для оценки ошибки обобщения без необходимости полагаться на отдельный набор для проверки. Эта оценка предоставляется «бесплатно», поскольку никаких дополнительных данных не требуется и может использоваться для выбора модели.
В настоящее время это реализовано в следующих классах:
ensemble.RandomForestClassifier([…]) | Классификатор случайных лесов. |
ensemble.RandomForestRegressor([…]) | Случайный лесной регрессор. |
ensemble.ExtraTreesClassifier([…]) | Классификатор дополнительных деревьев. |
ensemble.ExtraTreesRegressor([n_estimators, …]) | Регрессор с дополнительными деревьями. |
ensemble.GradientBoostingClassifier(*[, …]) | Повышение градиента для классификации. |
ensemble.GradientBoostingRegressor(*[, …]) | Повышение градиента для регресса. |